Pickleball & Longevity
Studien zufolge trägt die Trendsportart Pickleball in nahezu idealer Weise zur Langlebigkeit bei! Wer möchte nicht sein Leben bei guter Gesundheit um 10 Jahre verlängern? Mit Pickleball könnte das mit Freude und Spielspaß gelingen.
Copenhagen City Heart Study
Eine höchst beachtenswerte Studie ist die Copenhagen City Heart Study (CCHS).
Diese Langzeitstudie hatte 8577 Teilnehmer, die über einen Zeitraum von 25 Jahren (von Oktober 1991 bis März 2017) beobachtet wurden.
Es sollte untersucht werden, welcher Zusammenhang zwischen der Ausübung bestimmter Sportarten und der Lebenserwartung besteht. Verglichen mit einer Kontrollgruppe, die keine nennenswerte sportliche Aktivität ausübte ergab sich diese Reihenfolge der Erhöhung der Lebenserwartung:

Ja, von Pickleball ist hier noch nicht die Rede. Das liegt daran, dass diese Sportart 2017 noch keine große Popularität hatte. Ich werde den Zusammenhang gleich herstellen. Was haben die ersten drei Plätze gemeinsam?
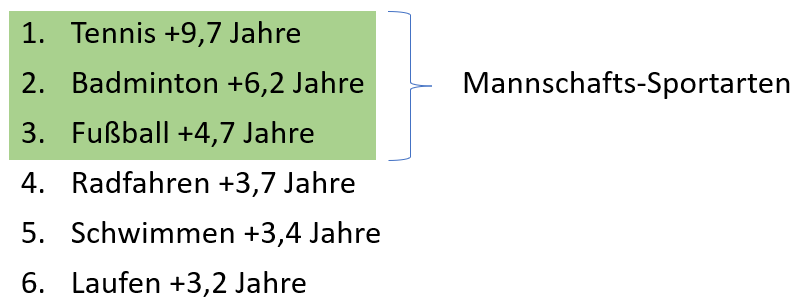
Mannschafts-Sportarten fördern die soziale Interaktion stärker als Sportarten, die auch allein betrieben werden können. Häufigere soziale Interaktion korreliert wiederum positiv mit Langlebigkeit. Platz 1 und 2 heben sich noch etwas vom dritten Platz ab. Was haben Tennis und Badminton gemeinsam?

Rückschlag-Sportarten erfordern nicht nur Kraft, Schnelligkeit und Ausdauer, sondern darüber hinaus stellen sie relativ hohe kognitive Anforderungen. Hand-Auge-Koordination ist stark gefordert, ebenso wie taktisches und situatives Verständnis und Reaktions-Schnelligkeit. Den Spitzenreiter dieser Rangfolge trennen allerdings immer noch stolze 3,5 Jahre zusätzlicher Lebenserwartung vom zweiten Platz. Woran könnte das liegen?

Während Badminton nahezu ausschließlich in der Halle gespielt wird, findet Tennis überwiegend auf Außenplätzen statt. Sport im Freien hat gesundheitliche Vorteile: Das wichtige Vitamin D kann dabei vom Körper hergestellt werden. Die Helligkeit ist draußen um ein Vielfaches stärker als in geschlossenen Räumen, was Depressionen vorbeugt.
Bis hierhin könnte man sagen: Glückwunsch an die Tennis-Spieler; alles richtig gemacht! Was hat das mit Pickleball zu tun? Hierzu möchte ich eine zweite große Studie anführen, die Apple Heart and Movement Study.
Apple Heart and Movement Study
Diese Studie wurde im Oktober 2023 durchgeführt und hat über 250.000 Pickleball- und Tennistrainings analysiert. Möglich war diese Analyse durch die Apple-Uhren, die dabei von den Spielern getragen wurden. Ich führe die Apple Heart and Movement Studie hier an, weil sie zeigt, dass die körperlichen Anforderungen von Tennis und Pickleball höchst ähnlich sind. Also sind auch ähnlich positive Effekte von Pickleball für die Langlebigkeit zu erwarten, zumal auch Pickleball sehr häufig draußen gespielt wird.

Die durchschnittliche Belastung beim Tennis ist etwas höher (um 9 Herzschläge pro Minute), dafür ist die durchschnittliche Dauer des Trainings beim Pickleball 9 Minuten länger. In Bezug auf soziale Interaktion steht die Pickleball-Community den Tennis-Spielern sicherlich nicht nach. Ein entscheidender Unterschied und Pluspunkt für Pickleball ist aber: Es ist erheblich leichter zu erlernen als Tennis! Das ist gerade für Menschen fortgeschrittenen Alters relevant, die zur Steigerung ihrer Gesundheit einen Rückschlag-Sport anfangen wollen.
Außerdem macht es einfach wahnsinnig viel Freude, Pickleball zu spielen! Und was man mit Freude tut, tut man öfters und regelmäßig, wie auch diese Erhebung in der Apple-Studie zeigt: Die Anzahl von Pickleball-Trainingseinheiten ist stetig gestiegen, während die Teilnahme an Tennis-Trainings starken Schwankungen unterlag.
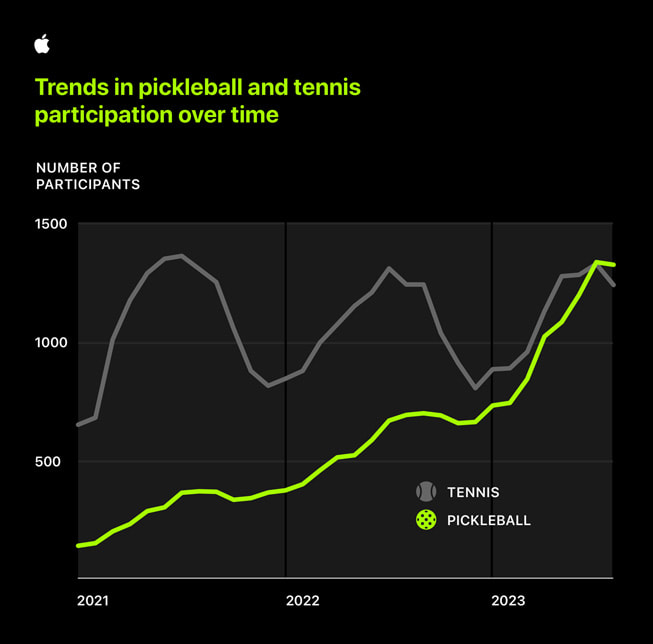
Quelle: Apple Heart and Movement Study
Zusammenfassend kann ich jedem, der an einer Verlängerung seiner Lebenserwartung durch Sport interessiert ist nur ans Herz legen, es einmal mit Pickleball zu versuchen! Pickleball spielen ist natürlich allemal besser als keinen Sport zu machen. Es scheint im Lichte der obigen Studien aber auch besser für die Langlebigkeit zu sein als manch anderer Kandidat, wie z.B. Laufen.
Pickleball spielen auf einem Badminton Feld
Ein Badminton-Spielfeld kann man sehr schnell und kostengünstig für Pickleball umwidmen. Das macht es für Sportlehrer und Sportvereine leicht, den Trendsport anzubieten.
Die Außenmaße eines Badminton-Doppelfeldes sind identisch mit den Außenmaßen eines Pickleball-Felds:

Badminton Spielfeld
Beim Pickleball gibt es übrigens keinen Unterschied in den Außenmaßen des Spielfelds bei Einzel oder Doppel. Also die Außenmaße sind schon mal gleich, da muß man gar nichts ändern. Nur die Auschlaglinie beim Badminton (in 1,98 m Entfernung vom Netz) ist nicht identisch mit der NVZ-Linie beim Pickleball:

Pickleball Spielfeld mit NVZ
Die NVZ ist in 2,13 m Abstand vom Netz. Man muß also nur jeweils eine Linie im Abstand von 15 cm von der Badminton-Aufschlaglinie aufkleben, schon hat man aus einem Badminton-Feld ein Pickleball-Feld gemacht!
Dafür eignet sich z.B. gut das Gauder Malerkrepp (ca. 12 Euro für drei Rollen); es läßt sich leicht aufkleben, hält gut und ist rückstandslos ablösbar. Hat man in 5 Minuten aufgeklebt:

Was noch fehlt ist ein Pickleball-Netz – das Badminton-Netz ist mit 1,55 m Höhe zu hoch. Ein mobiles Pickleball-Netz kostet unter 200 Euro und ist z.B. hier zu bekommen.

Mobiles Pickleball-Netz
Da gibt es übrigens auch kostengünstige Einsteigersets und Schläger mit einem guten Preis/Leistungsverhältnis und Mengenrabatten zu kaufen. Mit anderen Worten: Schulen und Sportvereine mit Zugang zu Badminton-Plätzen können mit wenig Aufwand und Kosten Pickleball anbieten! Und tatsächlich tun das immer mehr auch in Deutschland. Wir stehen meiner Meinung nach hierzulande vor einem Boom dieser Sportart.
Pickleball Trends

Es gibt eine Reihe von bemerkenswerten Entwicklungen und Veränderungen beim Pickleball, die ich hier mal kurz aus meiner Sicht aufzeigen und zur Diskussion stellen möchte.
Wachstum
Kürzlich erhobene Statistiken und Umfragen weisen darauf hin, dass Pickleball in den USA geradezu explosionsartig an Beliebtheit gewonnen hat. Ich hatte noch Zahlen von ca. 5 Millionen Spielern in 2022 dort im Kopf, aber aktuell sind es wohl über 30 Millionen! Siehe z.B. hier. Das zeigt uns auch das gigantische Potenzial, das dieser Sport in Deutschland hat.
Jeder Schlag mit Topspin
Mittlerweile sieht man bei den Profis, dass sie praktisch jeden Schlag mit Topspin spielen: Aufschläge, Returns, Dinks, Volleys und auch 3rd Shot Drops.
Beim Aufschlag kommt noch gelegentlich ein seitlicher Slice (Curve Serve) vor.
Beim Return ist der Slice praktisch nicht mehr anzutreffen. Der Hintergrund dabei ist wohl, dass der Return mit Slice es dem Aufschläger leichter macht, den Ball relativ platt mit viel Kraft und Geschwindigkeit zu schlagen, wobei der Slice vom Return sich in Topspin beim Gegenschlag verwandelt und der Ball so trotz hoher Geschwindigkeit im Feld bleibt.
Offensive Dinks werden jetzt häufig mit Topspin gespielt, was die Chancen auf einen Pop-Up der Gegner erhöht.
Roll-Volleys mit Topspin erlauben es, den Ball auch unter Netzhöhe offensiv zu spielen.
Auch beim 3rd Shot Drop wird jetzt sehr häufig Topspin eingesetzt. Der macht einen Stop-Ball schwerer und erhöht auch wieder die Chancen, einen hohen Ball zu bekommen.
Beidhändige Rückhand ist angesagt
So gut wie alle Pros – auch die Herren – spielen mittlerweile die Rückhand beidhändig oder arbeiten daran, sie zukünftig so spielen zu können. Prominentestes Beispiel ist Ben Johns. Hintergrund dabei ist, dass man so mit der Rückhand mehr Druck machen und offensivere Bälle schlagen kann. Außerdem hat man bei Rückhand-Dinks mehr Kontrolle. Einhändig wird die Rückhand von den meisten Profis nur noch bei sonst nicht zu erreichenden Bällen eingesetzt.
Mehr und mehr Tennisspieler wechseln zu Pickleball
Das beobachte ich auch in Deutschland. In den USA führt das mittlerweile dazu, dass die Profi-Ligen immer mehr Zulauf von Tennisprofis aus der zweiten Reihe bekommen. Das macht es den etablierten Pros schwerer – selbst Ben Johns gewinnt nicht mehr jedes Turnier. Das Spiel wird dadurch m.E. athletischer und noch stärker wettkampforientiert. Was ja nicht schlecht sein muss.
Mehr Power, weniger Soft Game
Vermutlich teilweise bedingt durch den letzten Punkt (mehr Tennisspieler) sehe ich, dass heute vielfach harte Schläge gespielt werden, wo früher ein Drop Shot oder ein Dink kam. Stichwort Banger. Das fällt mir besonders bei den Profi-Damen auf. Deren Spiel ist viel schneller und härter geworden, und lange Dink-Duelle gibt es da kaum noch. Zwar glaube ich nicht, dass das Soft Game ganz verschwinden wird – nicht, solange es noch die NVZ gibt – aber es nimmt an Bedeutung ab. Das finde ich vor allem im Hinblick auf Neueinsteiger etwas problematisch, denn es fällt ihnen damit vermutlich schwerer, überhaupt ein Soft Game zu entwickeln. Warum Dinken, wenn ich mit einem harten Drive die Rally gewinnen kann? Machen die Pros doch auch so.
Schläger
Nicht wenige der oben beschriebenen Entwicklungen und Veränderungen hängen mit der Weiterentwicklung des Materials zusammen. Ohne die Carbon-Oberflächen der Schläger gäbe es z.B. nicht die universelle Verwendung von Topspin. Außerdem gehen aktuelle Veränderungen des Materials in Richtung noch mehr Power. Bei älteren Schlägern mit Carbon-Oberfläche kam es gelegentlich vor, dass sich diese Oberfläche vom Schlägerkern teiweise gelöst hat (Delamination). Dadurch entsteht ein Trampolineffekt, der den Ball stärker beschleunigt. Das war also eigentlich eine unbeabsichtigte Nebenwirkung einer Verschleißerscheinung. Bei den neuesten Modellen – z.B. Joola Perseus 3 – wird mehr Power absichtlich durch die Füllung des Wabenkerns mit Schaum erreicht.

Diese Schläger führen gerade in den USA zu Kontroversen. Es gibt Bedenken, ob solche „Hochgeschwindigkeits-Schläger“ nicht zu gefährlich sein könnten bzw. das Spielkonzept von Pickleball nicht zu stark verändern würden. Abgesehen von solchen Bedenken haben Schläger mit so viel Durchschlagskraft natürlich nicht nur Vorteile: Die Kontrolle leidet, Platzierung und Verteidigung (Stichwort Reset) wird schwerer. Gerüchten zufolge spielt Ben Johns selbst gar nicht wirklich mit dem Perseus 3, sondern nach wie vor mit dem Perseus 2, der nur für die Optik einen blauen Rand bekommen hat 😉
Schlägerzulassung und Kontrolle
In den USA müssen Schläger durch die USAP zugelassen werden. Außerdem werden bei Turnieren Kontrollen durchgeführt, ob die Schläger den Regeln entsprechen. Darum musste der Hersteller CRBN etwa Schläger zurückrufen, weil ihre Oberfläche zu rauh war. Schläger mit Delamination (Trampolineffekt) oder zu rauhen Oberflächen können wegen der Kontrollen bei wichtigen Turnieren nicht eingesetzt werden. Möglicherweise werden in der Folge noch Schläger der dritten Generation durch die USAP verboten, aufgrund der oben genannten Bedenken. * In Deutschland gibt es solche Zulassungen und Kontrollen bisher meines Wissens nicht. Mit wachsender Verbreitung und Bedeutung des Sports sollte sich das aber ändern. Hoffe ich zumindest.
*: Das ist inzwischen tatsächlich passiert. Die Zulassung von Gen3 Joola Schlägern ist (temporär?) entzogen worden!
Pickleball spielen auf YouTube


