Pickleball Lingo

Viele Fachgebiete und Sportarten haben eine eigene Terminologie entwickelt, so auch Pickleball. Als Neuling fragt man sich dann oft: Wovon reden die da? Ich habe hier mal die gängigsten Ausdrücke erläutert. Da die Sportart aus den USA kommt, sind sie alle auf Englisch. Vielleicht prägen wir ja im Laufe der Zeit und mit steigender Beliebtheit des Sports hierzulande auch ein paar deutsche Begriffe. Die Aufstellung enthält nur die Ausdrücke, die spezifisch für Pickleball sind. Darum ist der Dink dabei, aber der Drive nicht.
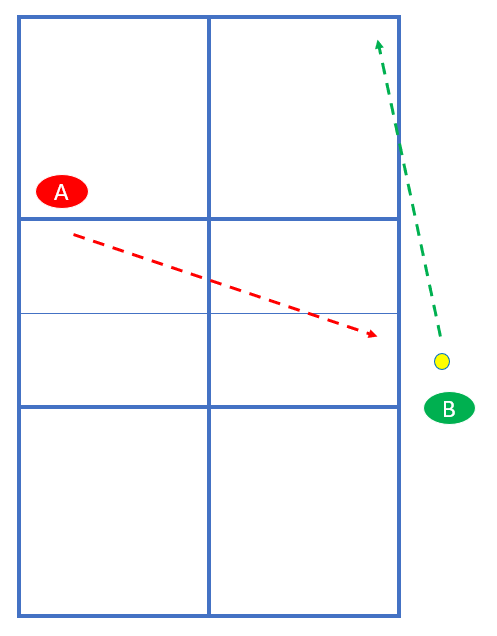
ATP (Around the post)
Wenn der Ball nach dem Aufsprung weit genug außerhalb des Spielfelds fliegt, darf man ihn am Netz vorbei (und unter Netzhöhe) zurückspielen. Das kann z.B. nach einem Cross-Dink vorkommen:
Banger
Das ist ein (meist abwertender) Ausdruck für Spieler, die fast ausschließlich mit harten Drives agieren und kaum mal einen -> Dink oder einen -> Drop Shot spielen.
Chicken Wing
Wenn man einen Volley mit der Rückhand spielt, obwohl der Ball eigentlich auf der Vorhandseite ist. Kommt öfters nach einem -> Speed-Up vor, weil viele Spieler an der -> NVZ den Schläger leicht in Richtung Rückhand bereithalten.
Dink
Ein kurzer Ball in die NVZ oder kurz hinter deren Linie, der möglichst nicht attackiert werden kann.
Drop Serve
Wenn der Ball beim Aufschlag fallen gelassen wird, um ihn nach dem Aufsprung zu schlagen. Hier ist ein Artikel dazu mit Einzelheiten.
Drop Shot (auch 3rd Shot Drop)
Ein Ball von der Grundlinie oder der -> Transition Zone, der in der NVZ oder kurz dahinter landet. Wird typischerweise vom aufschlagenden Team gespielt, um an die NVZ vorrücken zu können.
Erne
Diese spezielle Technik ist nach Erne Perry benannt, der sie besonders oft und erfolgreich angewandt hat. Man darf ja nicht in die NVZ treten, wenn Volley gespielt wird. Aber im Sprung darf man sie überfliegen, den Volley spielen und anschließend außerhalb des Spielfelds landen!

Golden Pickle
Wenn der sehr seltene Fall eintritt, dass man mit dem ersten Aufschlag alle Punkte (11:0:2) bis zum Spielgewinn macht.
Kitchen / Küche (siehe NVZ)
Nasty Nelson
Dieser Ball ist benannt nach Tim Nelson, der ihn oft erfolgreich praktiziert hat. Beim Aufschlag darf der vorn stehende Partner des Return-Spielers den Ball nicht berühren. Ein Nasty Nelson ist der Versuch, diesen vorn stehenden Partner mit dem Aufschlag zu treffen, um so einen Punkt zu machen. Könnte aber für schlechte Stimmung sorgen 😉
NVZ (Nicht-Volley-Zone)
Der Bereich von 2,13 Metern auf jeder Seite vom Netz, innerhalb dessen man keinen Volley spielen darf.
Poaching
Wenn ein Spieler den Ball auf der Seite seines Partners spielt – obwohl dieser den Ball auch erreichen könnte.
Pop-Up
Wenn man an der NVZ eigentlich einen Dink spielen wollte, aber der Ball gerät unbeabsichtigt zu hoch.
Rally-Scoring
Normalerweise kann man nur bei eigenem Aufschlag Punkte machen. Rally-Scoring bedeutet, dass man auch beim Return punkten kann.
Reset
Wenn man unter Druck einen kurzen Ball in die NVZ spielt.
Roll-Volley
Ein Volley mit Topspin und leichtem Handgelenkeinsatz.
Shake & Bake
Nach dem Aufschlag sind beide Spieler zunächst in Erwartung des Returns hinten. Shake & Bake bedeutet, dass man auf den Return einen harten Drive spielt und der Partner in Erwartung eines hohen Balls schon nach vorn an die NVZ läuft.
Speed-Up
Wenn man an der NVZ auf einen Dink der Gegner einen schnellen Ball spielt statt eines Dink.
Stacking
Eine Methode, mit der man stets auf der bevorzugten Seite spielen kann. Ich habe hier einen Artikel dazu geschrieben.
Transition Zone (auch Niemandsland)
Der Bereich zwischen Grundlinie und NVZ. Als Aufschläger muss man häufig in Etappen durch die Transition Zone an die NVZ vorrücken.
Von Tennis zu Pickleball – Starthilfe

Wegen der steigenden Bekanntheit von Pickleball in Deutschland sehe ich in letzter Zeit immer mehr Tennis-Spieler, die mit Pickleball anfangen. Dieser Artikel ist als Starthilfe für euch vielleicht hilfreich.
Die gute Nachricht vorweg: Typischerweise habt ihr mit einem Tennis-Hintergrund sehr gute Voraussetzungen, um mit Pickleball schnell Erfolgserlebnisse zu haben. Und weil Pickleball auf einem kleineren Platz, mit einem langsameren Ball und meistens im Doppel gespielt wird, ist es auch die ideale Alternative, wenn Tennis aus körperlichen Gründen nicht mehr so gut für euch funktioniert.
Schläger
Ich empfehle euch einen Schläger der sogenannten „elongated“ Form (also etwas verlängert und etwas schmaler als die normale Form) mit Carbon-Oberfläche. Diese Schläger sind den euch vertrauten Tennisschlägern vom Handling und vom Spielgefühl ähnlicher als die mit normaler Form. Und die Carbon-Oberfläche bewirkt, dass ihr wenigstens etwas Spin in die Schläge bekommen könnt – wenn auch bei weitem nicht so viel wie vom Tennis gewohnt. Ein Flaggschiff dieses Schlägertyps ist der Joola Perseus, aber natürlich gibt es auch weniger kostspielige Modelle mit ähnlichen Eigenschaften.

Griffhaltung
Ich empfehle den Continental-Griff als universale Griffhaltung. Man ist beim Pickleball meist schnell vorn am Netz, da ist keine Zeit mehr zum Umgreifen. Darum ist dieser Griff, mit dem man schnell Vor- und Rückhand-Volleys im Wechsel spielen kann eine gute Wahl.

Aufschlag
Im Pickleball ist der Aufschlag wesentlich harmloser und leichter zu lernen als im Tennis. Außerdem sind Aufschläger gegenüber den Rückschlägern taktisch im Nachteil. Das bedeutet für euch also eine gewisse (mentale) Umstellung. Ich habe hier einen Artikel zum Aufschlag veröffentlicht. Von der Technik her sollte das für euch aber jedenfalls keine Hürde sein.
Kein Serve & Volley im Pickleball
Stefan Edberg würde Pickleball nicht mögen! Die Regeln machen Serve & Volley bei uns unmöglich, denn der erste Return muss aufspringen. Das bedeutet, dass man nach dem Aufschlag zunächst in Erwartung des Returns hinten bleiben muss, denn der Return kommt typischerweise lang.
Nicht in die Küche treten beim Volley!
Eine Besonderheit beim Pickleball ist die Non-Volley-Zone – die aus einem mir unbekannten Grund gern „Kitchen“ also Küche genannt wird. Das sind 2,13 Meter auf jeder Seite vom Netz:

Wenn man in der NVZ steht, darf man nicht Volley spielen. Das kommt einem zuerst wie eine höchst lästige Schikane vor – es ist doch so natürlich, vorn ans Netz zu laufen und da drauf zu hauen! Ich kann gar nicht sagen, wie oft mir das als Einsteiger passiert ist. Nach ein paar Tagen gewöhnt ihr euch dran. Später werdet ihr die Küche zu schätzen lernen, denn mit einem klugen Ball in die NVZ hat man unter Druck immer eine gute Chance, zurück ins Spiel zu kommen. Man kann sagen, die NVZ ist erfunden worden, damit möglichst lange Ballwechsel entstehen können!
Volleys
Reaktions-Schnelligkeit und Ballgefühl könnt ihr gut von Tennis auf Pickleball transferieren. Der typische Slice-Volley vom Tennis funktioniert zunächst auch beim Pickleball. Allerdings solltet ihr euch im Laufe der Zeit besser den sogenannten Roll-Volley angewöhnen. Dieser Schlag erfolgt mit Topspin und leichtem Handgelenkeinsatz – was für Tennisspieler gewöhnungsbedürftig ist, aber Tischtennisspielern besonders leicht von der Hand geht. Der Vorteil des Roll-Volleys gegenüber dem Slice-Volley: Er kann auch offensiv mit Bällen gespielt werden, die leicht unter Netzhöhe gefallen sind. Und ein harter Roll-Volley landet dank des Topspin auch eher im Feld.
Drives
Eine gute Technik bei Vorhand- und Rückhanddrives kann leicht von Tennis auf Pickleball übertragen werden. Ihr könnt nur nicht soviel Spin in die Bälle bekommen wie beim Tennis. Gewöhnt euch also an, den Ball etwas platter zu treffen. Und seid nicht überrascht, wenn trotz eurer sehr guten Drives der Ball umgehend zurückkommt. Die Ballwechsel sind im Pickleball im Durchschnitt länger als im Tennis, weil das Spiel so entworfen wurde.
Keine Grundlinienduelle
Auch Björn Borg hätte wohl (zunächst) wenig Freude an Pickleball, denn man kann es nicht von der Grundlinie spielen. Hier ist ein Video, das die grundlegende Strategie beim Pickleball erläutert. Typischerweise stehen innerhalb der ersten fünf Bälle alle vier Spieler vorn an der NVZ und spielen Dinks. Übrigens spielt Ivan Lendl mittlerweile begeistert Pickleball!
Dinks?
Ein Dink ist ein kurzer Ball in die NVZ oder kurz hinter deren Linie, der möglichst nicht attackiert werden kann. Dieser Aspekt des Spiels fällt euch vielleicht zunächst etwas schwerer als andere Schlagarten, denn so ein Schlag kommt im Tennis kaum vor. Wenn alle vier Spieler an der NVZ stehen geht es darum, den Ball taktisch klug zu platzieren und auf einen zu hohen Ball der Gegner zu warten. Geduld und Ballsicherheit sind hier Trumpf, oft gewinnt man diese Rallys auch durch unerzwungene Fehler (etwa Ball ins Netz) der Gegner.
Fazit: Machen!
Wenn ihr also als Tennispieler überlegt, mit Pickleball anzufangen, kann ich nur sagen: Unbedingt machen! Ihr habt für diesen Sport ideale Vorkenntnisse und werdet schnell viel Spaß und Erfolgserlebnisse haben. So, wie Steffi Graf, Andre Agassi, und John McEnroe 😉
Pickleball Übung: Grosser Hosenträger
Diese Übung eignet sich gut zum Aufwärmen für etwas fortgeschrittene Spieler – denn man muss dabei den Ball schon relativ genau und sicher im Spiel halten können:

Vier Spieler stehen im Halbfeld. Spieler A startet mit einem Cross-Ball zu D. D spielt longline zu B. B spielt cross zu C. C spielt longline zu A. Und dann wieder von vorn.
A und B spielen also immer cross und C und D immer longline. Motivation und Spaß steigen, wenn jeder Spieler beim Schlag laut mitzählt: A: „1!“, D: „2!“, B: „3!“, C:“4!“, A:“5!“ etc.
Ziel ist es, bis 12 zu kommen. Passiert vorher ein Fehler, wird wieder von vorn begonnen. Ist die 12 erreicht, kann man die Schlagrichtung wechseln. Jetzt spielen A und B immer longline und C und D spielen immer cross.
Die Übung ist beendet, wenn zweimal die 12 erreicht worden ist.
Ist man nur zu zweit, kann man einen kleinen Hosenträger spielen. Dabei spielt ein Partner immer gerade und der andere immer abwechselnd auf die Vorhand und die Rückhand. Diese Variante kann allerdings etwas anstrengend werden, wenn man sie im Halbfeld oder gar von der Grundlinie spielt 😉
Pickleball spielen auf YouTube


