Beiträge getaggt mit ASM
Brief introduction to ASM mirroring
Automatic Storage Management (ASM) is becoming the standard for good reasons. Still, the way it mirrors remains a mystery for many customers I encounter, so I decided to cover it briefly here.
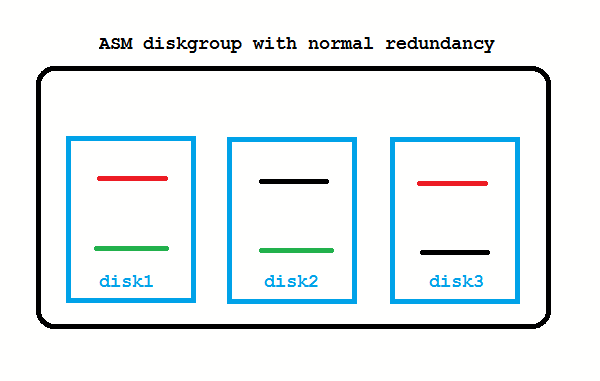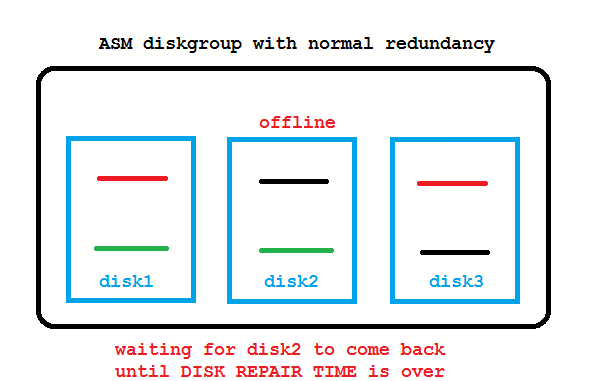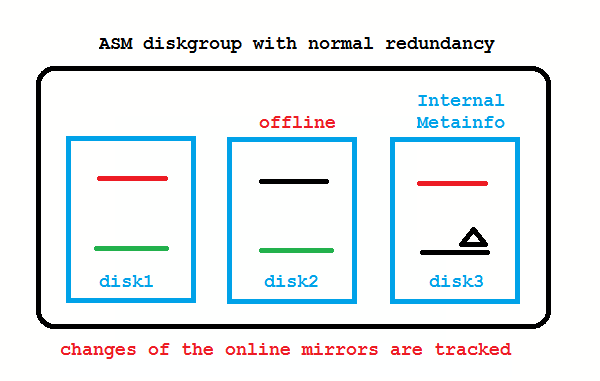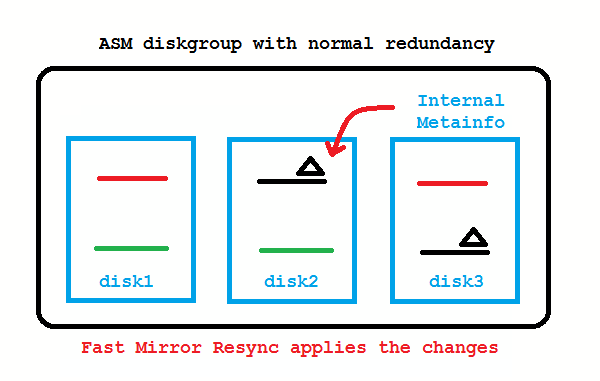
ASM Basics: What does normal redundancy mean at all?

It means that every stripe is mirrored once. There is a primary on one disk and a mirror on another disk. All stripes are spread across all disks. High redundancy would mean that every primary stripe has two mirrors, each on another disk. Obviously, the mirroring reduces the usable capacity: It’s one half of the raw capacity for normal redundancy and one third for high redundancy. The normal redundancy as on the picture safeguards against the loss of any one disk.
ASM Basics: Spare capacity

When disks are lost, ASM tries to re-establish redundancy again. Instead of using spare disks, it uses spare capacity. If enough free space in the diskgroup is left (worth the capacity of one disk) that works as on the picture above.
ASM 11g New Feature: DISK_REPAIR_TIME
What if the disk from the picture above is only temporarily offline and comes back online after a short while? These transient failures have been an issue in 10g, because the disk got immediately dropped, followed by a rebalancing to re-establish redundancy. Afterwards an administrator needed to add the disk back to the diskgroup which causes again a rebalancing. To address these transient failures, Fast Mirror Resync was introduced:
No administrator action required if the disk comes back before DISK_REPAIR_TIME (default is 3.6 hours) is over. If you don’t like that, setting DISK_REPAIR_TIME=0 brings back the 10g behavior.
ASM 12c New Feature: FAILGROUP_REPAIR_TIME
If you do not specify failure groups explicitly, each ASM disk is its own failgroup. Failgroups are the entities across which mirroring is done. In other words: A mirror must always be in another failgroup. So if you create proper failgroups, ASM can mirror according to your storage layout. Say your storage consists of four disk arrays (each with two disks) like on the picture below:

That is not yet the new thing, failgroups have been possible in 10g already. New is that you can now use the Fast Mirror Resync feature also on the failgroup layer with the 12c diskgroup attribute FAILGROUP_REPAIR_TIME. It defaults to 24 hours.
So if maintenance needs to be done with the disk array from the example, this can take up to 24 hours before the failgroup gets dropped.
I hope you found the explanation helpful, many more details are here 🙂
Drop an ASM Disk that contains a Voting Disk?
That was a question I got during my present Oracle 11gR2 RAC accelerated course in Duesseldorf: What happens if we drop an ASM Disk that contains a Voting Disk? My answer was: „I suppose that is not allowed“ but my motto is „Don’t believe it, test it!“ and that is what I did. That is actually one of the good things about doing a course at Oracle University: We can just check out things without affecting critical production systems here in our course environment:
[grid@host01 ~]$ crsctl query css votedisk
## STATE File Universal Id File Name Disk group
-- ----- ----------------- --------- ---------
1. ONLINE 48d3710843274f88bf1eb9b3b5129a7d (ORCL:ASMDISK01) [DATA]
2. ONLINE 354cfa8376364fd2bfaa1921534fe23b (ORCL:ASMDISK02) [DATA]
3. ONLINE 762ad94a98554fdcbf4ba5130ac0384c (ORCL:ASMDISK03) [DATA]
Located 3 voting disk(s).
We are on 11.2.0.1 here. The Voting Disk being part of an ASM Diskgroup was an 11gR2 New Feature that I introduced in this posting already. Now let’s try to drop ASMDISK01:
[grid@host01 ~]$ sqlplus / as sysasm SQL*Plus: Release 11.2.0.1.0 Production on Wed Jun 13 17:18:21 2012 Copyright (c) 1982, 2009, Oracle. All rights reserved. Connected to: Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - Production With the Real Application Clusters and Automatic Storage Management options SQL> select * from v$version; BANNER -------------------------------------------------------------------------------- Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - Production PL/SQL Release 11.2.0.1.0 - Production CORE 11.2.0.1.0 Production TNS for Linux: Version 11.2.0.1.0 - Production NLSRTL Version 11.2.0.1.0 - Production SQL> select name,group_number from v$asm_diskgroup; NAME GROUP_NUMBER ------------------------------ ------------ DATA 1 ACFS 2 FRA 3 SQL> select name from v$asm_disk where group_number=1; NAME ------------------------------ ASMDISK01 ASMDISK02 ASMDISK03 ASMDISK04 SQL> alter diskgroup data drop disk 'ASMDISK01'; Diskgroup altered.
It just did it without error message! We look further:
SQL> select name from v$asm_disk where group_number=1; NAME ------------------------------ ASMDISK02 ASMDISK03 ASMDISK04 SQL> exit Disconnected from Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - Production With the Real Application Clusters and Automatic Storage Management options [grid@host01 ~]$ crsctl query css votedisk ## STATE File Universal Id File Name Disk group -- ----- ----------------- --------- --------- 1. ONLINE 354cfa8376364fd2bfaa1921534fe23b (ORCL:ASMDISK02) [DATA] 2. ONLINE 762ad94a98554fdcbf4ba5130ac0384c (ORCL:ASMDISK03) [DATA] 3. ONLINE 3f0bf16b6eb64f3cbf440a3c2f0da2fd (ORCL:ASMDISK04) [DATA] Located 3 voting disk(s).
It just moved the Voting Disk silently to another ASM Disk of that Diskgroup. When I try to drop another ASM Disk from that Diskgroup, the command seems to be silently ignored, because 3 ASM Disks are required here to keep the 3 Voting Disks. Similar behavior with External Redundancy:
[grid@host01 ~]$ asmcmd lsdg State Type Rebal Sector Block AU Total_MB Free_MB Req_mir_free_MB Usable_file_MB Offline_disks Voting_files Name MOUNTED EXTERN N 512 4096 1048576 9788 9645 0 9645 0 N ACFS/ MOUNTED NORMAL N 512 4096 1048576 7341 6431 438 2996 0 N DATA/ MOUNTED EXTERN N 512 4096 1048576 4894 4755 0 4755 0 N FRA/
I will move the Voting Disk to the FRA Diskgroup. It is a bug of 11.2.0.1 that the Voting_files flag is not Y for the DATA Diskgroup here, by the way.
[grid@host01 ~]$ sudo crsctl replace votedisk +FRA Successful addition of voting disk 4d586fbecf664f8abf01d272a354fa67. Successful deletion of voting disk 354cfa8376364fd2bfaa1921534fe23b. Successful deletion of voting disk 762ad94a98554fdcbf4ba5130ac0384c. Successful deletion of voting disk 3f0bf16b6eb64f3cbf440a3c2f0da2fd. Successfully replaced voting disk group with +FRA. CRS-4266: Voting file(s) successfully replaced [grid@host01 ~]$ crsctl query css votedisk ## STATE File Universal Id File Name Disk group -- ----- ----------------- --------- --------- 1. ONLINE 4d586fbecf664f8abf01d272a354fa67 (ORCL:ASMDISK10) [FRA] Located 1 voting disk(s). [grid@host01 ~]$ sqlplus / as sysasm SQL*Plus: Release 11.2.0.1.0 Production on Wed Jun 13 17:36:06 2012 Copyright (c) 1982, 2009, Oracle. All rights reserved. Connected to: Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - Production With the Real Application Clusters and Automatic Storage Management options SQL> alter diskgroup fra drop disk 'ASMDISK10'; Diskgroup altered. SQL> exit Disconnected from Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - Production With the Real Application Clusters and Automatic Storage Management options [grid@host01 ~]$ crsctl query css votedisk ## STATE File Universal Id File Name Disk group -- ----- ----------------- --------- --------- 1. ONLINE 0b051cf6e6a14ff1bf31ef7bc66098e0 (ORCL:ASMDISK11) [FRA] Located 1 voting disk(s).
Not sure whether I would dare that all in a production system, though 🙂
Conclusion: We can drop ASM Disks that contain Voting Disks as long as there are enough Disks left in the Diskgroup to retain the same number of Voting Disks (each inside a separate Failure Group) afterwards. Apparently – but: „Don’t believe it, test it!“
No DISK_REPAIR_TIME on Exadata Cells
Starting with version 11.2.1.3.1, Exadata Cells use Pro-Active Disk Quarantine to override any setting of DISK_REPAIR_TIME. This and some other topics related to ASM mirroring on Exadata Storage Servers is explained in a recent posting of my dear colleage Joel Goodman. Even if you are familiar with ASM on non-Exadata Environments, you may not have used ASM redundancy yet and therefore benefit from his explanations about it.
Addendum: Maybe the headline is a little misleading as I just got aware. DISK_REPAIR_TIME set on an ASM Diskgroup that is built upon Exadata Storage Cells is still in use and valid. It is just not referring to the Disk level (Griddisk on Exadata) but instead on the Cell level.
In other words: If a physical disk inside a Cell gets damaged, the Griddisks built upon this damaged disk get dropped from the ASM Diskgroups immediately without waiting for DISK_REPAIR_TIME, due to Pro-Active Disk Quarantine. But if a whole Cell goes offline (Reboot of that Storage Server, for example), the dependant ASM disks get not dropped from the respective Diskgroups for the duration of DISK_REPAIR_TIME.
Pickleball spielen auf YouTube


