Beiträge getaggt mit High Availability
#Exasol Fail-Safety explained
The building blocks of an Exasol cluster are commodity Intel servers like e.g. Dell PowerEdge R740 with 96 GB RAM,12 x 1.2 TB SAS Hot-plug hard-drives and 2 x 10Gb Ethernet Cards for the private network. That’s sufficient to deliver outstanding performance combined with high availability. The picture below shows a 4+1 cluster, one of our most popular configurations:

Exasol 4+1 Cluster: Shared Nothing Architecture
Each active node hosts one database instance that works on its part of the database (A,B,C,D) in an MPP way. The instances communicate over the private network. Optionally, the private network can be separated into one database network and one storage network. In this case, the instances communicate over the database network. Notice that the instances access their part of the database directly on their local hard drives, they do not need the private network respectively the storage network for that. The reserve node becomes relevant only if one of the active nodes fails. The local hard drives are being setup in RAID 1 pairs, so single disk failures can be tolerated without losing database availability. Not listed is the license node that is required to boot the cluster initially. After that, the license node is no longer required to keep the cluster running.
If data volumes with redundancy 2 are in use – which is the most common case – then each node holds a copy of the data operated on by a neighbor node:

Exasol 4+1 Cluster: Redundancy 2
If a Master-Segment like A is modified, the Slave-Segment (A‘) is synchronized accordingly over the private network respectively the storage network.
Availability comes with a price: The raw disk capacity is reduced by half because of the RAID 1 mirroring and again by half because of the redundancy 2, so you remain with approximately (Linux OS and database software also require a small amount of disk space) 1/4 of your raw disk capacity. But since we are running on commodity hardware – no storage servers, no SAN, no SSDs required etc. – this is actually a very competitive price.
Now what if one node fails?

Exasol 4+1 Cluster: Node failure
ExaClusterOS – Exasols Clusterware – will detect the node failure within seconds and shutdown all remaining database instances in order to preserve a consistent state of the database. Then it restarts them again on the still available 3 nodes and also on the Reserve node that now becomes an Active node too. The database itself becomes available again with the node n15 now immediately working with segment B‘.
The downtime of the system caused by the node failure is below 30 seconds typically. The restart of the database triggers a threshold called Restore Delay which defaults to 10 Minutes. If within that time the failed node becomes available again, we will just re-synchronize the segments (A‘ and B in the example) which can be done fast. The instance on n15 will then work with the segment B as a Master-Segment until the database is manually restarted. Then n15 becomes a reserve node again and n12 is active with an instance running there.
If the failed node doesn’t come back within Restore Delay:

Exasol 4+1 Cluster: Restore Delay is over
We will then create new segments on node n15: A‘ is copied from n11 and B is copied from n13. This activity is time-consuming and puts a significant load on the private network, which is why configuring a dedicated storage network may be beneficial to avoid a drop in performance during that period. A new reserve node should now be added to the cluster, replacing the crashed n12.
Foreign Archived Log in #Oracle – what does it mean?
When you look into V$RECOVERY_AREA_USAGE, you see a strange row at the bottom:
SQL> select * from v$recovery_area_usage;
FILE_TYPE PERCENT_SPACE_USED PERCENT_SPACE_RECLAIMABLE NUMBER_OF_FILES CON_ID
----------------------- ------------------ ------------------------- --------------- ----------
CONTROL FILE 0 0 0 0
REDO LOG 0 0 0 0
ARCHIVED LOG 10.18 0 73 0
BACKUP PIECE 0 0 0 0
IMAGE COPY 0 0 0 0
FLASHBACK LOG 0 0 0 0
FOREIGN ARCHIVED LOG 0 0 0 0
AUXILIARY DATAFILE COPY 0 0 0 0
Curious what that could be? You will see values other than zero on a Logical Standby Database:
SQL> connect sys/oracle@logst as sysdba
Connected.
SQL> select database_role from v$database;
DATABASE_ROLE
----------------
LOGICAL STANDBY
SQL> select * from v$recovery_area_usage;
FILE_TYPE PERCENT_SPACE_USED PERCENT_SPACE_RECLAIMABLE NUMBER_OF_FILES CON_ID
----------------------- ------------------ ------------------------- --------------- ----------
CONTROL FILE 0 0 0 0
REDO LOG 0 0 0 0
ARCHIVED LOG 14.93 0 9 0
BACKUP PIECE 0 0 0 0
IMAGE COPY 0 0 0 0
FLASHBACK LOG 0 0 0 0
FOREIGN ARCHIVED LOG 2.03 0 26 0
AUXILIARY DATAFILE COPY 0 0 0 0
In contrast to a Physical Standby Database, this one writes not only into standby logs but also into online logs while being in standby role. That leads to two different kinds of archive logs:
 When DML (like insert and update) is done on the primary 1) that leads to redo entries into online logs 2) that are simultaneously shipped to the standby and written there into standby logs 2) also. The online logs on the primary and the standby logs on the standby will be archived 3) eventually. So far that is the same for both physical and logical standby. But now a difference: Logical standby databases do SQL Apply 4) by logmining the standby or the archive logs that came from the primary. That generates similar DML on the standby which in turn leads LGWR there to write redo into online logs 5) that will eventually get archived 6) as well.
When DML (like insert and update) is done on the primary 1) that leads to redo entries into online logs 2) that are simultaneously shipped to the standby and written there into standby logs 2) also. The online logs on the primary and the standby logs on the standby will be archived 3) eventually. So far that is the same for both physical and logical standby. But now a difference: Logical standby databases do SQL Apply 4) by logmining the standby or the archive logs that came from the primary. That generates similar DML on the standby which in turn leads LGWR there to write redo into online logs 5) that will eventually get archived 6) as well.
A logical standby could do recovery only with its own archive logs (if there was a backup taken before) but not with the foreign archive logs. Therefore, those foreign archive logs can and do get deleted automatically. V$ARCHIVED_LOG and V$FOREIGN_ARCHIVED_LOG can be queried to monitor the two different kinds of logs.
That was one topic of the course Oracle Database 12c: Data Guard Administration that I delivered as an LVC – therefore the picture. Hope you find it useful 🙂
Let the Data Guard Broker control LOG_ARCHIVE_* parameters!
When using the Data Guard Broker, you don’t need to set any LOG_ARCHIVE_* parameter for the databases that are part of your Data Guard configuration. The broker is doing that for you. Forget about what you may have heard about VALID_FOR – you don’t need that with the broker. Actually, setting any of the LOG_ARCHIVE_* parameters with an enabled broker configuration might even confuse the broker and lead to warning or error messages. Let’s look at a typical example about the redo log transport mode. There is a broker configuration enabled with one primary database prima and one physical standby physt. The broker config files are mirrored on each site and spfiles are in use that the broker (the DMON background process, to be precise) can access:
 When connecting to the broker, you should always connect to a DMON running on the primary site. The only exception from this rule is when you want to do a failover: That must be done connected to the standby site. I will now change the redo log transport mode to sync for the standby database. It helps when you think of the log transport mode as an attribute (respectively a property) of a certain database in your configuration, because that is how the broker sees it also.
When connecting to the broker, you should always connect to a DMON running on the primary site. The only exception from this rule is when you want to do a failover: That must be done connected to the standby site. I will now change the redo log transport mode to sync for the standby database. It helps when you think of the log transport mode as an attribute (respectively a property) of a certain database in your configuration, because that is how the broker sees it also.
[oracle@uhesse1 ~]$ dgmgrl sys/oracle@prima DGMGRL for Linux: Version 11.2.0.3.0 - 64bit Production Copyright (c) 2000, 2009, Oracle. All rights reserved. Welcome to DGMGRL, type "help" for information. Connected. DGMGRL> edit database physt set property logxptmode=sync; Property "logxptmode" updated
In this case, physt is a standby database that is receiving redo from primary database prima, which is why the LOG_ARCHIVE_DEST_2 parameter of that primary was changed accordingly:
[oracle@uhesse1 ~]$ sqlplus sys/oracle@prima as sysdba SQL*Plus: Release 11.2.0.3.0 Production on Tue Sep 30 17:21:41 2014 Copyright (c) 1982, 2011, Oracle. All rights reserved. Connected to: Oracle Database 11g Enterprise Edition Release 11.2.0.3.0 - 64bit Production With the Partitioning, OLAP and Data Mining options SQL> show parameter log_archive_dest_2 NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ log_archive_dest_2 string service="physt", LGWR SYNC AFF IRM delay=0 optional compressi on=disable max_failure=0 max_c onnections=1 reopen=300 db_uni que_name="physt" net_timeout=3 0, valid_for=(all_logfiles,pri mary_role)
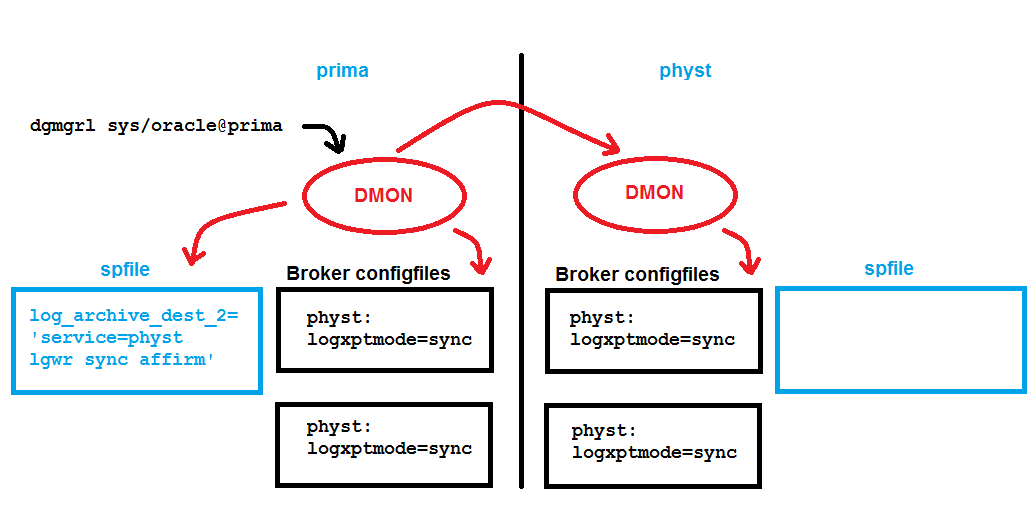
The mirrored broker configuration files on all involved database servers contain that logxptmode property now. There is no new entry in the spfile of physt required. The present configuration allows now to raise the protection mode:
DGMGRL> edit configuration set protection mode as maxavailability; Succeeded.
The next broker command is done to support a switchover later on while keeping the higher protection mode:
DGMGRL> edit database prima set property logxptmode=sync; Property "logxptmode" updated
Notice that this doesn’t lead to any spfile entry; only the broker config files store that new property. In case of a switchover, prima will then receive redo with sync.
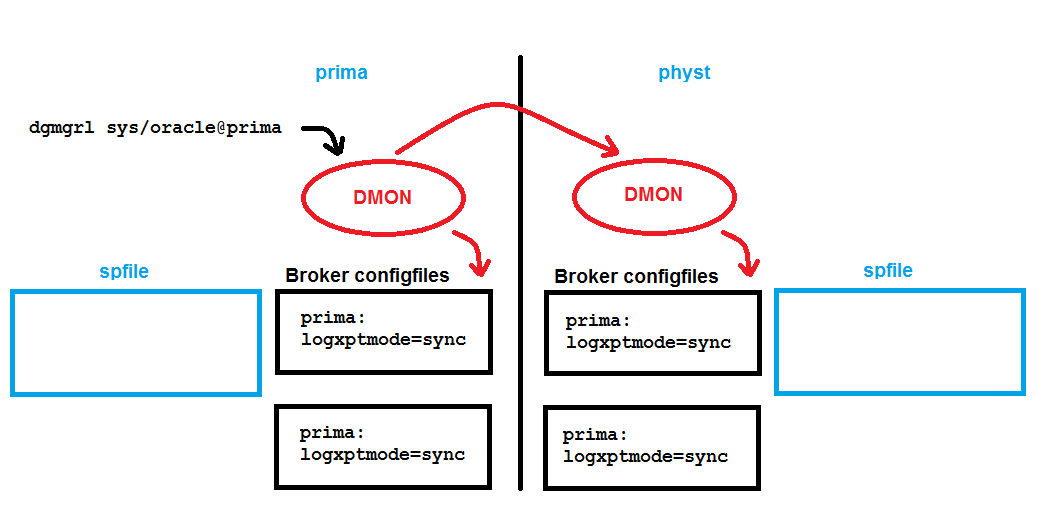 Now let’s do that switchover and see how the broker ensures automatically that the new primary physt will ship redo to prima:
Now let’s do that switchover and see how the broker ensures automatically that the new primary physt will ship redo to prima:
DGMGRL> show configuration;
Configuration - myconf
Protection Mode: MaxAvailability
Databases:
prima - Primary database
physt - Physical standby database
Fast-Start Failover: DISABLED
Configuration Status:
SUCCESS
DGMGRL> switchover to physt;
Performing switchover NOW, please wait...
New primary database "physt" is opening...
Operation requires shutdown of instance "prima" on database "prima"
Shutting down instance "prima"...
ORACLE instance shut down.
Operation requires startup of instance "prima" on database "prima"
Starting instance "prima"...
ORACLE instance started.
Database mounted.
Switchover succeeded, new primary is "physt"
All I did was the switchover command, and without me specifying any LOG_ARCHIVE* parameter, the broker did it all like this picture shows:
 Especially, now the spfile of the physt database got the new entry:
Especially, now the spfile of the physt database got the new entry:
[oracle@uhesse2 ~]$ sqlplus sys/oracle@physt as sysdba SQL*Plus: Release 11.2.0.3.0 Production on Tue Oct 14 15:43:41 2014 Copyright (c) 1982, 2011, Oracle. All rights reserved. Connected to: Oracle Database 11g Enterprise Edition Release 11.2.0.3.0 - 64bit Production With the Partitioning, OLAP and Data Mining options SQL> show parameter log_archive_dest_2 NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ log_archive_dest_2 string service="prima", LGWR SYNC AFF IRM delay=0 optional compressi on=disable max_failure=0 max_c onnections=1 reopen=300 db_uni que_name="prima" net_timeout=3 0, valid_for=(all_logfiles,pri mary_role)
Not only is it not necessary to specify any of the LOG_ARCHIVE* parameters, it is actually a bad idea to do so. The guideline here is: Let the broker control them! Else it will at least complain about it with warning messages. So as an example what you should not do:
[oracle@uhesse1 ~]$ sqlplus sys/oracle@prima as sysdba SQL*Plus: Release 11.2.0.3.0 Production on Tue Oct 14 15:57:11 2014 Copyright (c) 1982, 2011, Oracle. All rights reserved. Connected to: Oracle Database 11g Enterprise Edition Release 11.2.0.3.0 - 64bit Production With the Partitioning, OLAP and Data Mining options SQL> alter system set log_archive_trace=4096; System altered.
Although that is the correct syntax, the broker now gets confused, because that parameter setting is not in line with what is in the broker config files. Accordingly that triggers a warning:
DGMGRL> show configuration;
Configuration - myconf
Protection Mode: MaxAvailability
Databases:
physt - Primary database
prima - Physical standby database
Warning: ORA-16792: configurable property value is inconsistent with database setting
Fast-Start Failover: DISABLED
Configuration Status:
WARNING
DGMGRL> show database prima statusreport;
STATUS REPORT
INSTANCE_NAME SEVERITY ERROR_TEXT
prima WARNING ORA-16714: the value of property LogArchiveTrace is inconsistent with the database setting
In order to resolve that inconsistency, I will do it also with a broker command – which is what I should have done instead of the alter system command in the first place:
DGMGRL> edit database prima set property LogArchiveTrace=4096;
Property "logarchivetrace" updated
DGMGRL> show configuration;
Configuration - myconf
Protection Mode: MaxAvailability
Databases:
physt - Primary database
prima - Physical standby database
Fast-Start Failover: DISABLED
Configuration Status:
SUCCESS
Thanks to a question from Noons (I really appreciate comments!), let me add the complete list of initialization parameters that the broker is supposed to control. Most but not all is LOG_ARCHIVE*
LOG_ARCHIVE_DEST_n
LOG_ARCHIVE_DEST_STATE_n
ARCHIVE_LAG_TARGET
DB_FILE_NAME_CONVERT
LOG_ARCHIVE_FORMAT
LOG_ARCHIVE_MAX_PROCESSES
LOG_ARCHIVE_MIN_SUCCEED_DEST
LOG_ARCHIVE_TRACE
LOG_FILE_NAME_CONVERT
STANDBY_FILE_MANAGEMENT
Pickleball spielen auf YouTube


