Beiträge getaggt mit RAC
HA of Database Control for RAC made easy
When you install an 11g RAC database without Grid Control respectively Cloud Control present, this is what the DBCA will give you:
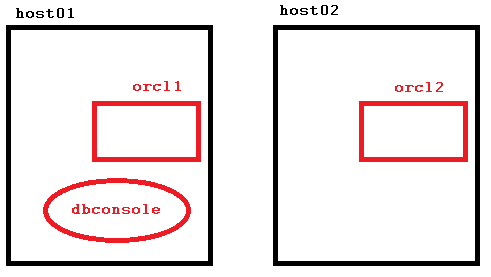 There is one Database Control OC4J Container only, running on host01. Should host01 go down, the Enterprise Manager is no longer available now. We could make that a resource, known to the clusterware and let it failover in that case. But also – and even easier – we can start a second OC4J Container to run on host02 simultaneously like this:
There is one Database Control OC4J Container only, running on host01. Should host01 go down, the Enterprise Manager is no longer available now. We could make that a resource, known to the clusterware and let it failover in that case. But also – and even easier – we can start a second OC4J Container to run on host02 simultaneously like this:
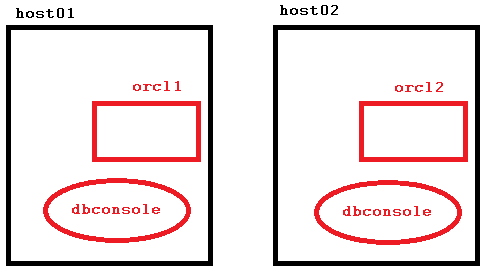 Let’s see how to implement that:
Let’s see how to implement that:
[oracle@host01 ~]$ emca -reconfig dbcontrol -cluster -EM_NODE host02 -EM_NODE_LIST host02
STARTED EMCA at May 14, 2014 5:16:14 PM
EM Configuration Assistant, Version 11.2.0.3.0 Production
Copyright (c) 2003, 2011, Oracle. All rights reserved.
Enter the following information:
Database unique name: orcl
Service name: orcl
Do you wish to continue? [yes(Y)/no(N)]: yes
May 14, 2014 5:16:26 PM oracle.sysman.emcp.EMConfig perform
INFO: This operation is being logged at /u01/app/oracle/cfgtoollogs/emca/orcl/emca_2014_05_14_17_16_14.log.
May 14, 2014 5:16:29 PM oracle.sysman.emcp.util.DBControlUtil stopOMS
INFO: Stopping Database Control (this may take a while) ...
May 14, 2014 5:16:34 PM oracle.sysman.emcp.EMAgentConfig performDbcReconfiguration
INFO: Propagating /u01/app/oracle/product/11.2.0/dbhome_1/host02_orcl/sysman/config/emd.properties to remote nodes ...
May 14, 2014 5:16:34 PM oracle.sysman.emcp.util.DBControlUtil startOMS
INFO: Starting Database Control (this may take a while) ...
May 14, 2014 5:17:33 PM oracle.sysman.emcp.EMDBPostConfig performDbcReconfiguration
INFO: Database Control started successfully
May 14, 2014 5:17:34 PM oracle.sysman.emcp.EMDBPostConfig showClusterDBCAgentMessage
INFO:
**************** Current Configuration ****************
INSTANCE NODE DBCONTROL_UPLOAD_HOST
---------- ---------- ---------------------
orcl host01 host01.example.com
orcl host02 host02.example.com
Enterprise Manager configuration completed successfully
FINISHED EMCA at May 14, 2014 5:17:34 PM
[oracle@host01 ~]$ emctl status dbconsole
Oracle Enterprise Manager 11g Database Control Release 11.2.0.3.0
Copyright (c) 1996, 2011 Oracle Corporation. All rights reserved.
https://host01.example.com:1158/em/console/aboutApplication
Oracle Enterprise Manager 11g is running.
------------------------------------------------------------------
Logs are generated in directory /u01/app/oracle/product/11.2.0/dbhome_1/host01_orcl/sysman/log
Not only can I access Database Control at host01 as usual, I can also get it at host02 now:
[oracle@host01 ~]$ ssh host02
Last login: Wed May 14 10:50:32 2014 from host01.example.com
[oracle@host02 ~]$ emctl status dbconsole
Oracle Enterprise Manager 11g Database Control Release 11.2.0.3.0
Copyright (c) 1996, 2011 Oracle Corporation. All rights reserved.
https://host02.example.com:1158/em/console/aboutApplication
Oracle Enterprise Manager 11g is running.
------------------------------------------------------------------
Logs are generated in directory /u01/app/oracle/product/11.2.0/dbhome_1/host02_orcl/sysman/log
All this is of course not new, but you won’t find it easy in the docs. That is something from my RAC accelerated course last week in Reading, by the way. Even seasoned RAC DBAs are sometimes not aware of that option, so I thought it might be helpful to publish it here briefly 🙂
#Oracle RAC One Node – Video
Based on the Grid Infrastructure, RAC One Node is a RAC Database with only one instance running. This architecture reduces unplanned as well as planned downtime. If the server crashes that holds the instance of a RAC One Node database, that instance can failover to another node in the cluster automatically. If we need to take down the server (or the clusterware stack there) because of a maintenance task, we can do an Online Database Relocation:
The demo was done with 11gR2 and it is very similar to what I show live during the Oracle University course Oracle Database 11g: RAC Administration about RAC One Node. Hope you like it 🙂
Purpose of the Voting Disk for #Oracle RAC
The Voting Disk provides an additional communication path for the cluster nodes in case of problems with the Interconnect. It prevents Split-Brain scenarios. That is another topic from my recent course Oracle Grid Infrastructure 11g: Manage Clusterware and ASM that I’d like to share with the Oracle Community.
Under normal circumstances, the cluster nodes are able to communicate through the Interconnect. Not only do the cssd background processes interchange a network heartbeat that way, but also things like Cache Fusion are done on that path. The red lines in the picture symbolize the cssd network heartbeat. Additionally, the cssd processes write also into the Voting Disk (respectively Voting File) regularly and interchange a disk heartbeat over that path. The blue lines in the picture stand for that path. Each cssd makes an entry for its node and for the other nodes it can reach over the network:
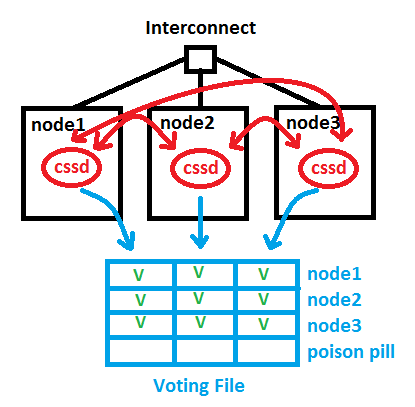 Now in case of a network error, a Split-Brain problem would occur – without a Voting Disk. Suppose node1 has lost the network connection to the Interconnect. In order to prevent that, redundant network cards are recommended since a long time. We introduced HAIP in 11.2.0.2 to make that easier to implement, without the need of bonding, by the way. But here, node1 cannot use the Interconnect anymore. It can still access the Voting Disk, though. Nodes 2 and 3 see their heartbeats still but no longer node1, which is indicated by the green Vs and red fs in the picture. The node with the network problem gets evicted by placing the Poison Pill into the Voting File for node1. cssd of node1 will commit suicide now and leave the cluster:
Now in case of a network error, a Split-Brain problem would occur – without a Voting Disk. Suppose node1 has lost the network connection to the Interconnect. In order to prevent that, redundant network cards are recommended since a long time. We introduced HAIP in 11.2.0.2 to make that easier to implement, without the need of bonding, by the way. But here, node1 cannot use the Interconnect anymore. It can still access the Voting Disk, though. Nodes 2 and 3 see their heartbeats still but no longer node1, which is indicated by the green Vs and red fs in the picture. The node with the network problem gets evicted by placing the Poison Pill into the Voting File for node1. cssd of node1 will commit suicide now and leave the cluster:
 The pictures in this posting are almost identical with what I paint on the whiteboard during the course. Hope you find it useful 🙂
The pictures in this posting are almost identical with what I paint on the whiteboard during the course. Hope you find it useful 🙂
Related posting: Voting Disk and OCR in 11gR2: Some changes
Pickleball spielen auf YouTube


