Der Aufschlag im #Pickleball
Das Beste vorweg: Der Aufschlag im Pickleball ist leicht zu lernen und auszuführen. Anders als etwa im Tennis oder Tischtennis, wo man typischerweise viel Zeit mit der Übung des Aufschlags verbringt, um konkurrenzfähig zu sein. Die Regeln erschweren es zudem beträchtlich, dass der Aufschlag zur spielentscheidenden „Waffe“ werden kann. Asse oder zwingender Vorteil nach dem Aufschlag sind daher ziemlich selten.
Regeln
Die Regeln zur Positionierung gelten sowohl für den Volley-Serve als auch für den Drop-Serve:
Zum Zeitpunkt, wenn der Ball beim Aufschlag auf den Schläger trifft, müssen die Füße des aufschlagenden Spielers hinter der Grundlinie und innerhalb verlängerten Linien der jeweiligen Platzhälfte sein:

Der Oberkörper des Spielers und der Ball dürfen sich dabei innerhalb des Spielfelds befinden. Außerdem darf der Spieler das Spielfeld betreten, unmittelbar nachdem der Ball den Schläger verlassen hat.
Vorher aber nicht:
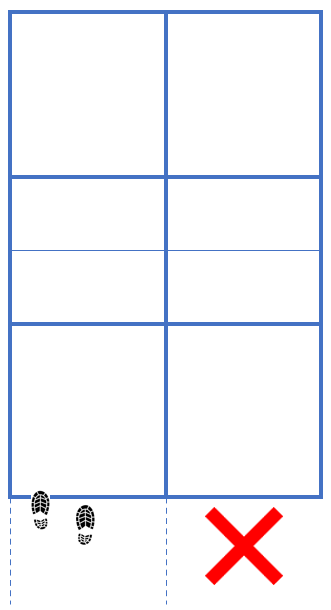
Schon das Berühren der Grundlinie mit der Fußspitze beim Aufschlag ist ein Fehler.
Man darf auch nicht beliebig weit außen stehen:

Der linke Fuß ist hier außerhalb der verlängerten Linien der linken Platzhälfte, weshalb dieser Aufschlag nicht regelgerecht wäre.
Wer schlägt wann wohin auf, und was ist mit der NVZ?
Es muss jeweils das diagonal gegenüberliegende Feld getroffen werden, wobei der Ball nicht in der NVZ landen darf. Die Linien gehören dabei zur NVZ: Ein Ball auf die hintere Linie der NVZ ist ein Fehler. Genauso gehören die Linien zum Aufschlagfeld: Ein Ball auf die Grundlinie oder ein Ball auf die Außenlinie ist also kein Fehler. Wird der Punkt gewonnen, wechselt der Aufschläger mit seinem Partner die Seite. Verliert der erste Aufschläger die Rally, macht sein Partner von der Seite weiter, wo er grad steht. Verliert auch der zweite Aufschläger die Rally, wechselt der Aufschlag auf das andere Team. Die Zählweise und die jeweilige Positionierung der Spieler hab ich in diesem Artikel behandelt.
Volley-Serve
Das ist derzeit der beliebteste Aufschlag und ursprünglich auch der einzig erlaubte Aufschlag. Der Ball wird dabei aus der Hand aufgeschlagen.
Der Schlägerkopf muss dabei eine Bewegung von unten nach oben ausführen, wie in 4-3 zu sehen.
Der Schlägerkopf darf sich zum Zeitpunkt des Auftreffen des Balls nicht über dem Handgelenk befinden (4-1 zeigt die korrekte Ausführung, 4-2 ist ein häufig zu beobachtender Fehler).
Außerdem muss der Ball unterhalb der Taille des Aufschlägers getroffen werden, wie in 4-3 zu sehen.

Das obige Bild stammt aus dem Official Rulebook der USAP.
Alle Regeln zum Volley-Serve sollen im Grunde sicherstellen, dass dieser Aufschlag eben nicht zum spielentscheidenden Vorteil wird. Im folgenden Clip sehen wir einen Aufschlag von Anna Leigh Waters, der momentan besten Spielerin der Welt:
Diese Art des Aufschlags ist bei den Pros am häufigsten zu sehen: Volley-Serve, Top-Spin, tief ins Feld gespielt. Wir sehen aber auch, dass ihre Gegenspielerin den Aufschlag ohne große Mühe returniert. Asse oder direkt aus dem Aufschlag resultierender Punktgewinn sind im Pickleball ziemlich selten. Ganz im Gegensatz etwa zu Tennis und Tischtennis.
Drop-Serve
Diese Art des Aufschlags ist erst seit 2021 erlaubt. Abgesehen von den oben beschriebenen Regeln zur Positionierung der Füße gibt es beim Drop-Serve nur eine weitere Regel: Der Ball muss aus der Hand fallengelassen werden. Hochwerfen oder nach unten Stoßen/Werfen des Balls ist nicht erlaubt. Insbesondere darf der Ball auf beliebige Art geschlagen werden. Das macht diesen Aufschlag besonders Einsteigerfreundlich, weil man kaum die Regeln verletzen kann.
Ich habe dem Drop-Serve bereits diesen Artikel gewidmet.
Abgesehen von den Regeln – wie sollte man aufschlagen?
Es gibt hier zwei grundsätzliche Herangehensweisen:
Die einen sagen, weil man mit dem Aufschlag ohnehin selten einen direkten Punkt macht, sollte man ihn nur möglichst sicher in das hintere Drittel des Felds reinspielen:
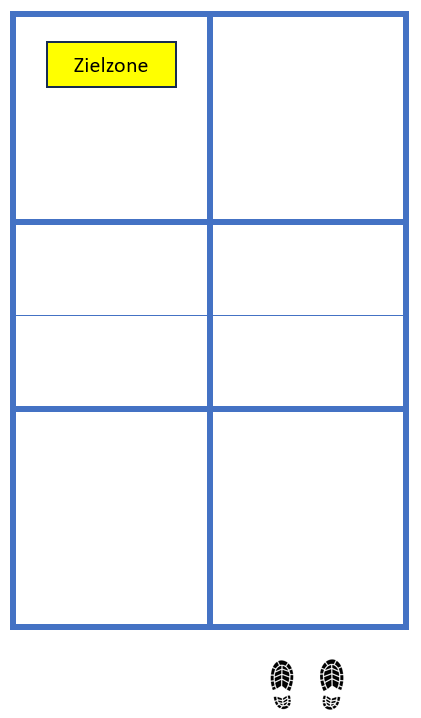
Ins hintere Drittel, weil die Rückschläger sonst zu leicht einen starken Return spielen und die Aufschläger hinten halten können. Mit der gelben Zielzone ist es unwahrscheinlich, dass der Aufschlag aus geht.
Die anderen (zu denen ich auch gehöre) sagen: Mit dem Aufschlag kann man ruhig etwas Risiko eingehen. Schließlich kann das Return-Team keinen Punkt machen. Es ist okay, wenn von 10 Aufschlägen 2 ausgehen und die übrigen 8 es den Rückschlägern schwer machen, uns hinten zu halten. Der eine oder andere direkte Punkt sollte auch dabei sein. Darum sehen meine Zielzonen so aus:

Die meisten Aufschläge gehen Richtung Zielzone 1, ab und an mal einer nach 2 und 3. Die roten Zonen sind deutlich näher an den Linien als die gelbe, was natürlich die Gefahr eines Ausballs erhöht.
Im Allgemeinen kann man zum Aufschlag im Pickleball sagen:
Länge ist wichtiger als Härte oder Spin. Ein entspannt in hohem Bogen ins hintere Drittel des Aufschlagfelds gelobbter Ball macht dem Rückschläger mehr Probleme als ein harter Topspin in die Mitte. Kurze Aufschläge sind sporadisch eingesetzt als Überraschungswaffe gut, ansonsten erleichtern sie es dem Rückschläger nur, nach vorn an die NVZ zu kommen.
Pickleball Übung: Drop Spiel 7-11
Einer der wichtigsten Schläge im Pickleball ist der 3rd Shot Drop – also der dritte Schlag einer Rally, wo das aufschlagende Team mittels eines kurzen Balls in die NVZ nach vorn kommen will.
Leider ist das auch ein ziemlich schwieriger Ball, weshalb er häufig geübt werden sollte.
Wenn es euch geht wie mir, findet ihr Spiele um Punkte viel spannender als Übungen. Darum hab ich mir dieses Spiel ausgedacht.
Es geht mit vier, drei oder sogar nur zwei Teilnehmern. Die Beschreibung ist für vier Spieler.
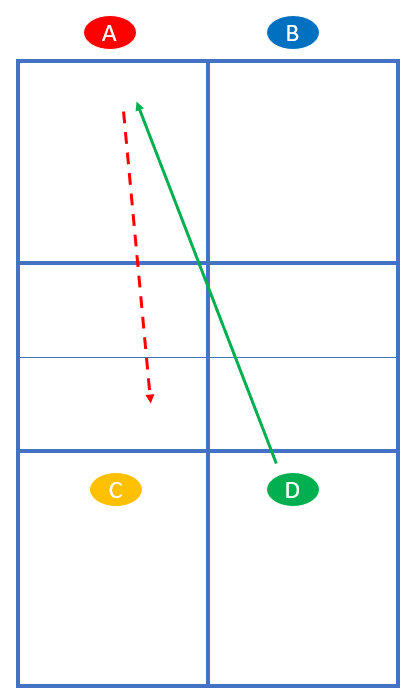
Spieler A und B sollen den Drop Shot üben. Sie stehen so, wie im normalen Spiel das aufschlagende Team vor dem 3. Schlag steht. Spieler C und D stehen so, wie im normalen Spiel das rückschlagende Team nach dem Return steht – nämlich an der NVZ. Hier in der Übung starten C und D jede Rally. Zuerst spielt D einen langen Ball diagonal. A versucht einen Drop Shot. Anschließend rücken A und B nach vorn:
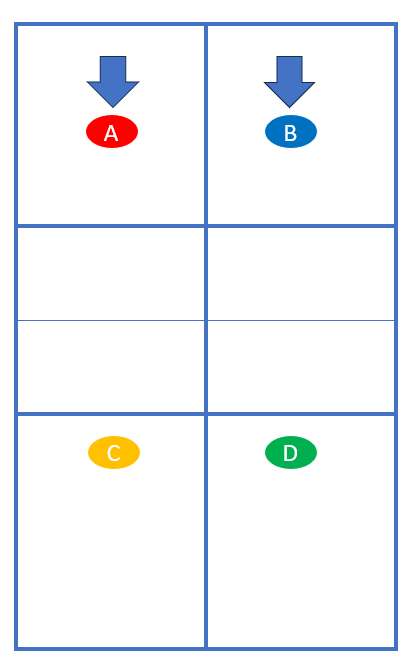
Je nachdem, wie gut der Drop Shot war, kommen sie gleich nach vorn oder rücken allmählich durch die Transition-Zone vor.
Das Spiel geht mit Rally-Scoring, also sowohl Team AB als auch Team CD können jederzeit Punkte machen. C und D starten abwechselnd die Rally. Ist also der erste Punkt ausgespielt, beginnt nun C:
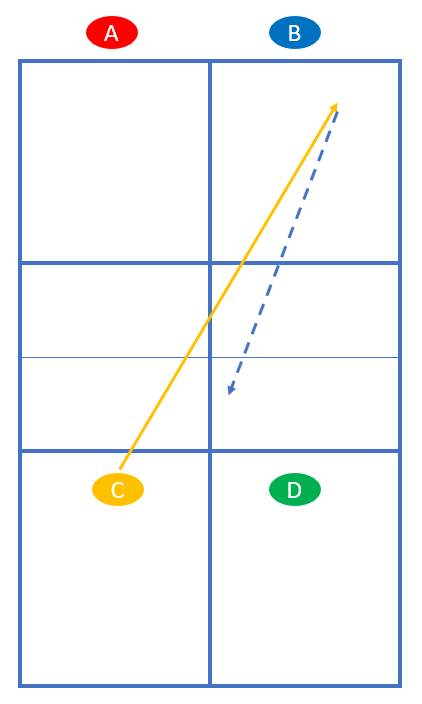
Für C und D ist es etwas leichter, Punkte zu machen als für A und B. Darum gewinnen C und D mit 11 Punkten, während A und B schon mit 7 Punkten gewinnen.
Sind nur drei Spieler am Start, übt einer den Drop Shot. Er wechselt dabei jeweils die Seite. Die Gegner dürfen nur auf diese Seite spielen.
Bei zwei Spielern spielt man nur auf einer Hälfte des Platzes.
Das Spiel hat für beide Teams einen guten Übungseffekt, denn diese Schläge sind typischerweise die kritischen Schläge jedes Ballwechsels bei fortgeschrittenen Spielern – und man spielt/übt eben nur diese.
Durch das Scoring bleibt die Motivation hoch. Bei unseren bisherigen Drop Spielen hat sich gezeigt, dass nach relativ kurzer Zeit häufiger das Drop Team mit 7 Punkten gewinnt. Das ist aber auch ganz okay so, finde ich. Denn das gibt ja das Feedback, dass man es mit dem Drop Shot richtig macht.
1, 2, 3 – Frei!
Pickleball Übung: 1, 2 , 3 – Frei!
Eine schöne Übung zum Aufwärmen, die auch gut für Einsteiger geeignet ist:
Alle vier Spieler stehen an der NVZ. Aufschlag und Zählweise ist wie beim normalen Spiel.
Die ersten drei Bälle inklusive des Aufschlags müssen in der NVZ aufkommen. Anschließend ist der Ball freigegeben für offensive Dinks, Speed-Ups und Lobs:

Beispiel: Spieler A beginnt mit dem Aufschlag diagonal, D dinkt (nicht zwingend) zu B und B spielt den dritten Ball in die Küche zu C. C spielt einen langen Ball in die Lücke.
Hintergrund: Wir haben die Übung bisher so ähnlich gespielt, aber mit 5 Bällen, die in die Küche gespielt werden müssen, bevor der Ball freigegeben wird.
Das hat in meinen Augen zwei Nachteile:
- Es lehrt die Teilnehmer die falsche Art von Dinks, nämlich harmlose „Dead Dinks“ in die Küche. Im ernsthaften Spiel geht es aber beim Dinken nicht in erster Linie darum, unbedingt in die Küche zu treffen. Ein Dink soll möglichst nicht angreifbar sein, aber möglichst unangenehm für den Gegner, damit der einen hohen Ball zurückspielt, den wir unsererseits angreifen können. Das kann durchaus auch ein Ball sein, der kurz hinter der NVZ aufspringt. Mit dem alten Übungsmodell ist das aber ein Fehler. Später hat man dann oft noch Schwierigkeiten, den Leuten die richtige Art von Dinks beizubringen.
- Man muss bis 5 die Bälle mitzählen. Das klappt oft nicht so gut, so dass man im Zweifel ist: Waren das jetzt schon 5?
Bei 1, 2, 3 – Frei! behält man leichter den Überblick. Trotzdem ist der Aufschläger (wie beim großen Spiel) etwas im Nachteil, denn die Rückschläger können zuerst einen offensiven Ball spielen. Eben zum Beispiel einen druckvollen Dink, kurz hinter die NVZ.
Pickleball spielen auf YouTube


