Pickleball Spaßturnier des DJK Agon 08
Der DJK Agon 08 hat erstmals ein Pickleball Spaßturnier durchgeführt. Das hat so gut geklappt und so viel Spaß gemacht, dass wir es sicher nächstes Jahr wiederholen werden!
19 Teilnehmer haben auf vier Plätzen gespielt – im Schnitt hat jeder 12 Spiele absolviert:

Der Modus war denkbar einfach: Jeder sollte möglichst mit jedem gegen jeden spielen – ohne Rücksicht auf Alter, Spielstärke und Geschlecht. Das kann man im Pickleball gut machen, denn das Spiel ist ohnehin sehr inklusiv ausgelegt. So sind auch bei uns heute sehr viele schöne und auch ausgeglichene Spiele entstanden. Viele sind recht knapp entschieden worden.
Zwischendurch war auch fürs leibliche Wohl gesorgt worden:

Es gab auch Medaillen zu gewinnen:

Nach über vier Stunden Spielzeit stand der Sieger mit Fabio fest: Er hatte 42 Punkte aus 16 Spielen erzielt! Dicht gefolgt von Carsten mit 35 Punkten aus 15 Spielen:

Michael hatte Bronze mit 34 Punkten aus 15 Spielen erreicht, war aber bei der Siegerehrung schon nicht mehr vor Ort.
Bei dem Turnier war auch ein gewisses Stehvermögen gefragt, denn wer wenig Pausen und viele Spiele machte hatte die besten Chancen auf die vorderen Plätze. Die Marke von 30 Punkten haben so hinter den drei ersten auch Andreas (30), Uwe (30), Annett (31) und Ross (33) geknackt!
Es hat uns bei diesem Turnier besonders gefreut, neben 7 DJK Mitgliedern auch 12 Teilnehmer aus anderen Vereinen begrüßen zu können.
Die Spiele waren jederzeit fair und freundlich, wie auch die gesamte Atmosphäre. Ich danke allen Teilnehmern herzlich für diese gemeinsame gelungene Aktion – das war erneut eine Werbung für unseren schönen Sport!
Pickleball Variante: Skinny Singles
Skinny Singles (Entschärftes Einzel) ist die geniale Lösung, wenn ihr eigentlich Doppel spielen wollt, aber nur zu zweit seid.
Doppel wird von den meisten Pickleball-Spielern bevorzugt. Normales Einzel ist doch recht anstrengend. Skinny Singles ist eine gute Alternative, wenn keine vier Spieler fürs Doppel zusammenkommen.
Video
Die Idee von Skinny Singles ist, dass man als jeweiliger Spieler nur etwa ein Viertel des Platzes abdecken muss, ähnlich wie beim Doppel. Das wird durch eine kleine Anpassung der Spielregeln erreicht:
Spielregel Skinny Singles auf den Punkt gebracht
Mein Score bestimmt, welches Platzviertel ich gerade abdecke: Ist mein Score gerade, steh ich rechts, ansonsten links. Und nur dahin darf mein Gegner dann auch spielen.
Beispiel
Beim Stand von 0 – 0 schlägt Spieler Grün von rechts auf, Spieler Rot schlägt von rechts zurück:
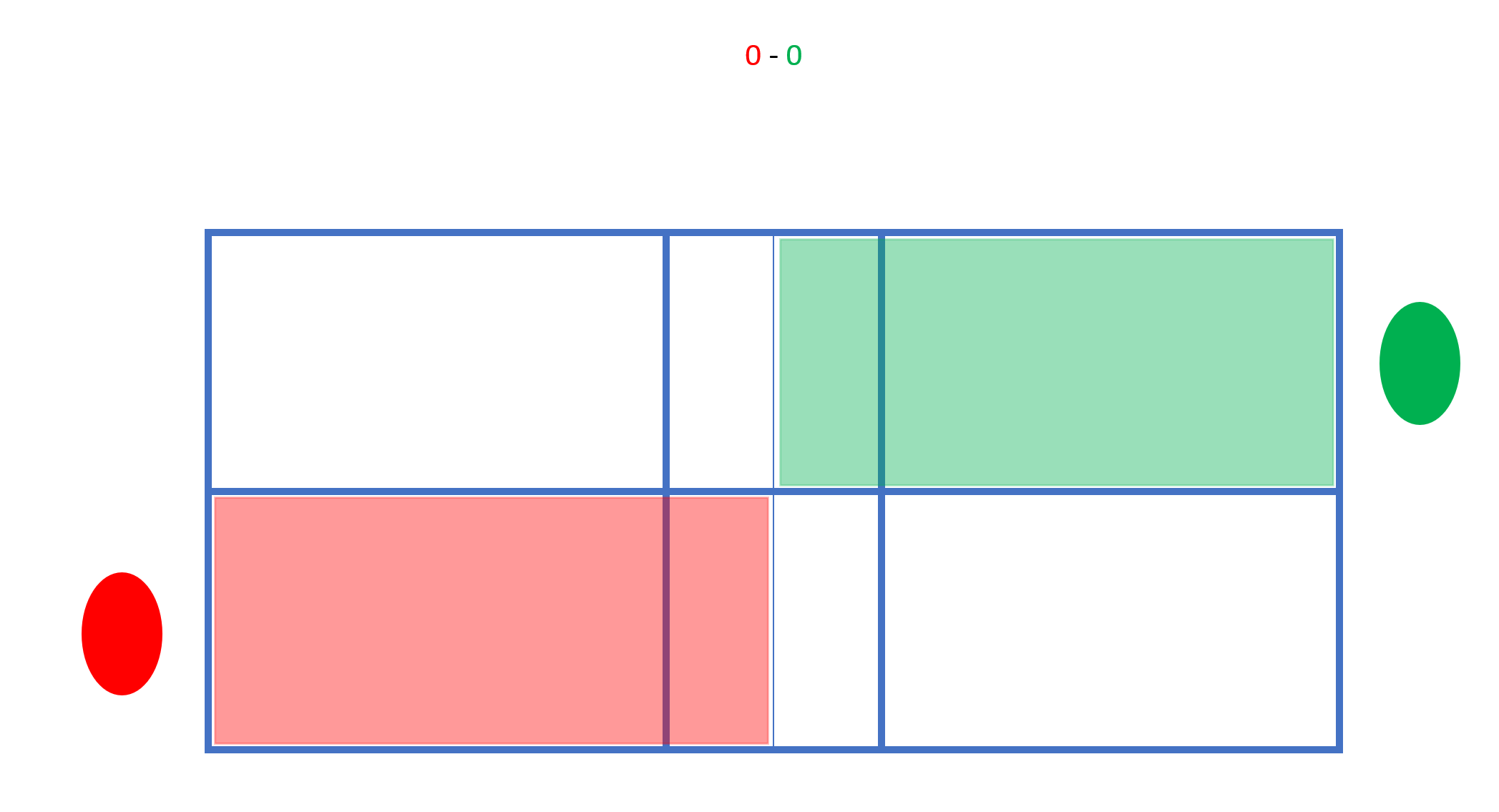
In der Folge darf nur in die jeweils markierte Fläche gespielt werden. Wenn Grün den Punkt macht, wechselt er nach links:
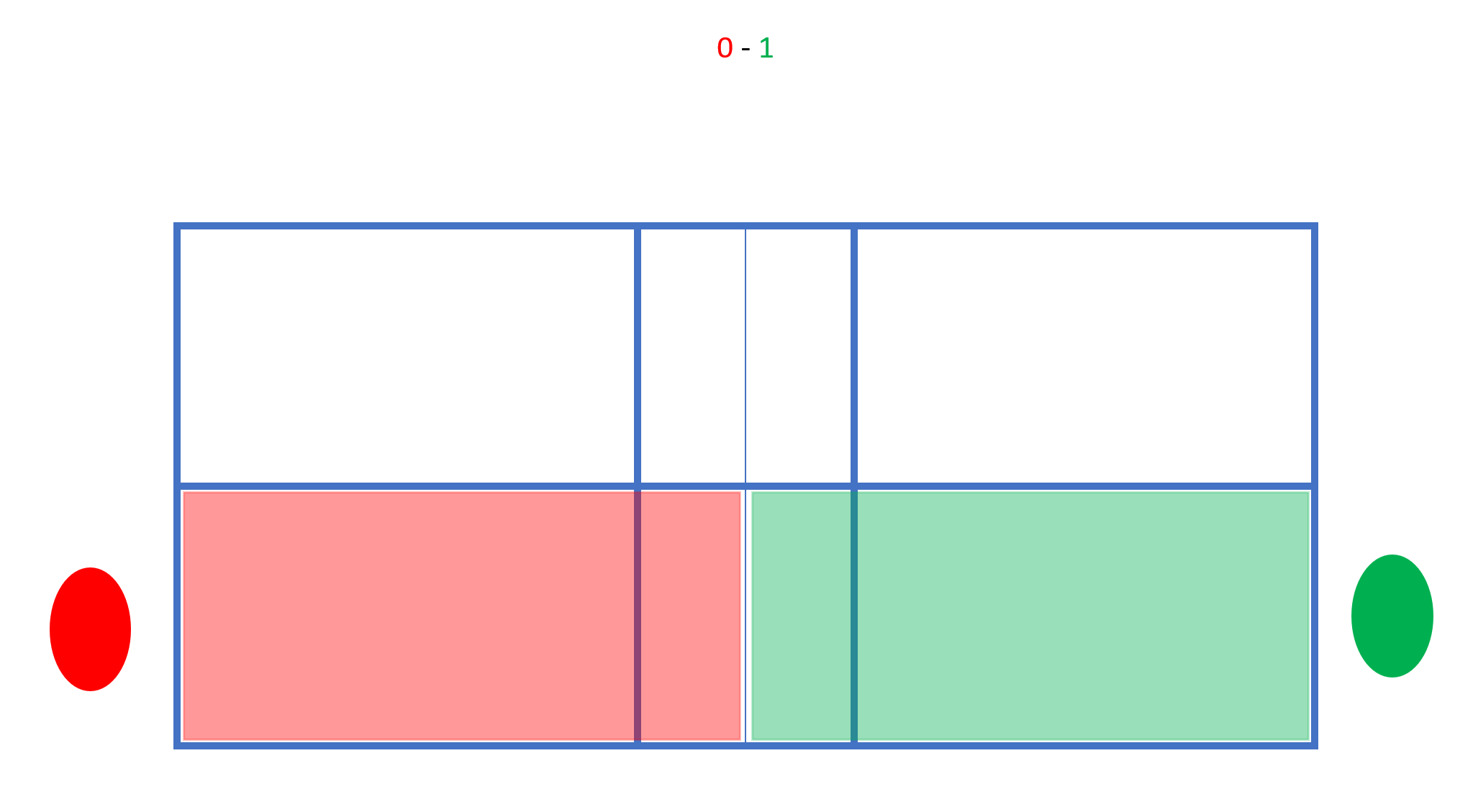
Rot bleibt gemäß seines geraden Spielstands rechts stehen. Grün schlägt also nicht diagonal sondern in das gerade gegenüber liegende Feld auf. Macht Grün erneut den Punkt, wechselt er wieder nach rechts, während Rot stehen bleibt:
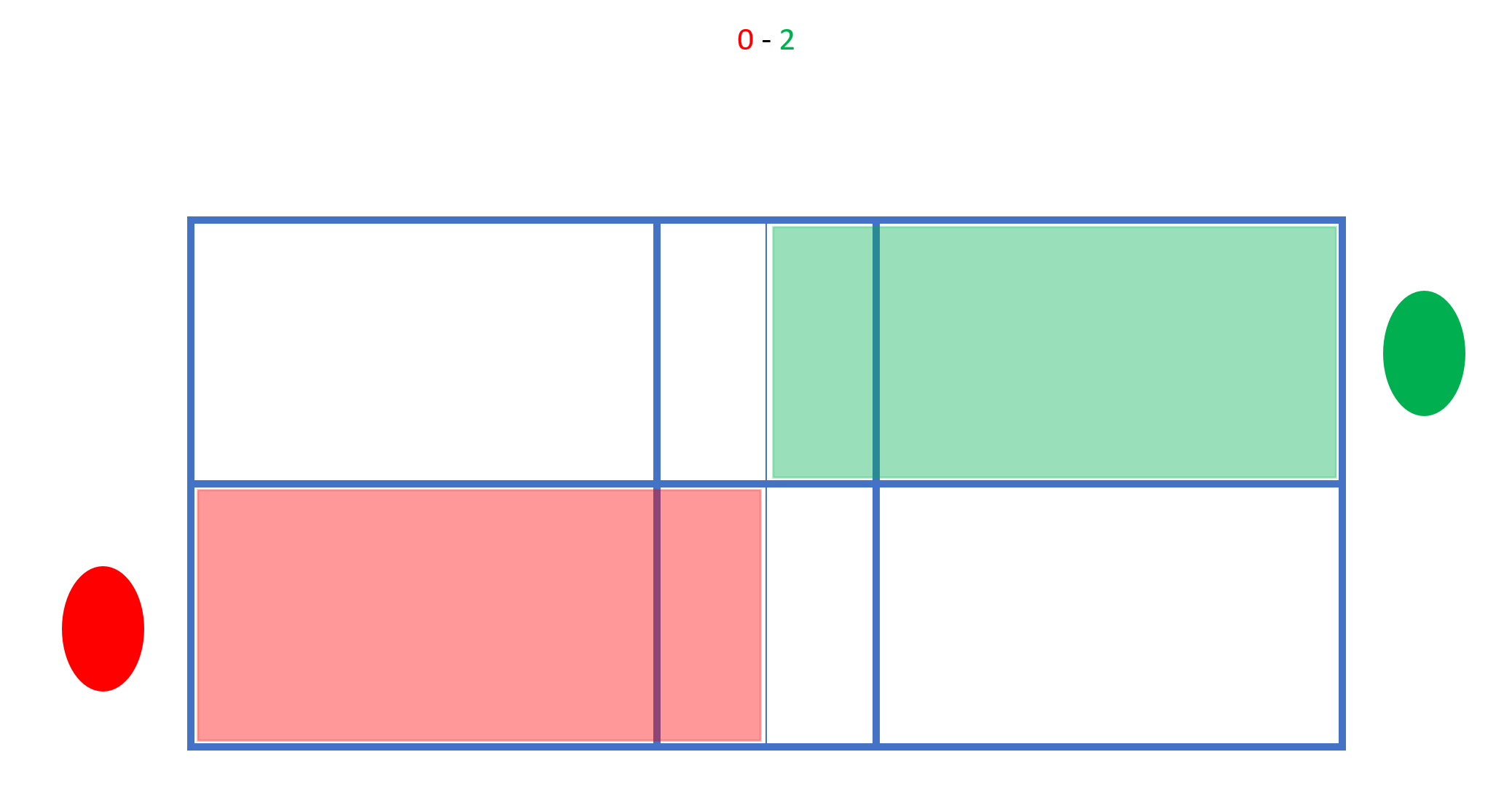
Gewinnt Rot nun die Rally, wechselt der Aufschlag zu ihm. Beide Spieler bleiben gemäß ihres geraden Spielstands rechts stehen.
Macht Rot nun einen Punkt, wechselt er mit dem Aufschlag nach links, während Grün gemäß seines Scores rechts stehen bleibt:

Und immer so weiter, bis 11.
Fazit
Skinny Singles hat also den Vorteil, dass es ein sehr Doppel-ähnliches Spiel ermöglicht, obwohl man nur zu zweit ist. Außerdem ist es ein gutes Training für Platzierung. Ich habe sogar in den USA schon Skinny Singles Turniere gesehen.
Vielleicht probiert ihr es einfach aus, wenn ihr das nächste Mal nur zu zweit seid: Viel Spaß! 🙂
Mit Pickleball anfangen

Du hast Gutes über Pickleball gehört und möchtest es mal ausprobieren? Gratuliere zu dieser Entscheidung, du wirst es nicht bereuen!
Wo kann man Pickleball spielen?
Das ist momentan so ziemlich die einzige Hürde beim Einstieg: Pickleball ist noch nicht so bekannt in Deutschland – das ändert sich aber gerade rasant! Die besten Chancen hast du als Einwohner Nordrhein-Westfalens, denn da gibt es mittlerweile in fast jeder größeren Stadt Vereine, die Pickleball anbieten. In der Landeshauptstadt natürlich sowieso. Aber auch in anderen Bundesländern gibt es Pickleball-Vereine. Hier ist eine Karte. Diese Facebook-Gruppe ist auch ein guter Ort, um Pickleball-Spielmöglichkeiten zu finden. Auf die Idee mit der Suchmaschine („Pickleball <Meine Stadt>“) bist du schon selbst gekommen 😉 Aus eigener Erfahrung weiß ich zudem, dass die Vereine nicht unbedingt zeitnah etwas auf ihren Webseiten veröffentlichen, auch wenn sie bereits eine Pickleball-Gruppe am Start haben. Es lohnt sich also, einfach mal den lokalen Verein deiner Wahl zu kontaktieren und nachzufragen!
Was braucht man an Ausrüstung?
Du brauchst nur ganz normale Sportbekleidung, die du ohnehin schon hast. Schläger und Bälle werden normalerweise von den Vereinen leihweise zur Verfügung gestellt. Insbesondere würde ich davon abraten, im Vorfeld schon Schläger zu kaufen. Die billigen Schläger (unter 50 Euro) sind einfach unbrauchbar, und die teureren solltest du besser erstmal ausleihen: Beim Verein oder bei dem netten Pickleball-Kumpel, der bereits sechs Schläger gekauft hat und gern einen davon für kleines Geld wieder abgibt.
Wie geht das Spiel eigentlich?
Pickleball ist leicht zu lernen, sowohl was die Spielweise als auch was die Regeln betrifft. Das erklären dir die Leute vor Ort innerhalb von 10 Minuten, dann kannst du schon loslegen und mitmachen. Nur die Zählweise beim Doppel ist vielleicht etwas gewöhnungsbedürftig, darum hab ich diesen kurzen Clip aufgenommen:
Soll ich wirklich mit Pickleball anfangen?
Kurze Antwort: Unbedingt! Lass uns mal die zwei üblichen vermeintlichen Hinderungsgründe durchgehen:
Ich bin zu alt / zu jung / zu unsportlich / zu unbegabt für Rückschlagspiele
Pickleball ist eins der inklusivsten Spiele der Welt: Jeder kann mit jedem im Doppel zusammenspielen und Spaß haben. Und zwar ziemlich schnell, ohne erst lange üben zu müssen. Insbesondere ist die Diskrepanz zwischen guten Spielern und Anfängern nicht derart groß, dass beide Seiten schnell frustriert sind. Mit anderen Worten: Die Anfänger verlieren zwar gegen die guten Spieler, aber es kommen trotzdem viele gute Ballwechsel zustande. Weil Pickleball einfach so entworfen wurde!
Ich kenn da ja keinen
Die Pickleball-Community ist sehr aufgeschlossen und wertschätzend gegenüber Neueinsteigern: Du findest garantiert schnell Anschluss und kannst mitspielen. Ich habe selbst schon andere Erfahrungen z.B. mit Tischtennis-Vereinen gemacht, wo man als Neuankömmling gern auch mal ignoriert wird und die alten Hasen am liebsten nur untereinander spielen. Das ist beim Pickleball völlig anders, keine Sorge!
Es ist gut fürs Herz
Pickleball hält nicht nur körperlich fit, es bringt auch gutes Karma 🙂 Diesen Song kann ich mir beispielsweise nicht über Golf vorstellen, aber bei Pickleball passt er genau:
Pickleball spielen auf YouTube


