The Voting Disk provides an additional communication path for the cluster nodes in case of problems with the Interconnect. It prevents Split-Brain scenarios. That is another topic from my recent course Oracle Grid Infrastructure 11g: Manage Clusterware and ASM that I’d like to share with the Oracle Community.
Under normal circumstances, the cluster nodes are able to communicate through the Interconnect. Not only do the cssd background processes interchange a network heartbeat that way, but also things like Cache Fusion are done on that path. The red lines in the picture symbolize the cssd network heartbeat. Additionally, the cssd processes write also into the Voting Disk (respectively Voting File) regularly and interchange a disk heartbeat over that path. The blue lines in the picture stand for that path. Each cssd makes an entry for its node and for the other nodes it can reach over the network:
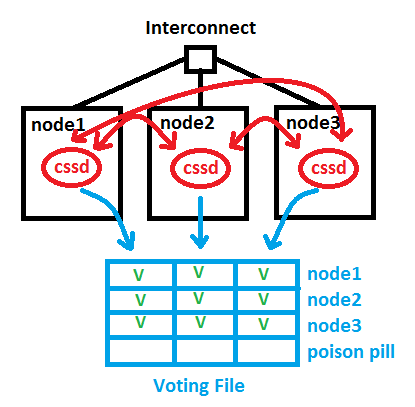 Now in case of a network error, a Split-Brain problem would occur – without a Voting Disk. Suppose node1 has lost the network connection to the Interconnect. In order to prevent that, redundant network cards are recommended since a long time. We introduced HAIP in 11.2.0.2 to make that easier to implement, without the need of bonding, by the way. But here, node1 cannot use the Interconnect anymore. It can still access the Voting Disk, though. Nodes 2 and 3 see their heartbeats still but no longer node1, which is indicated by the green Vs and red fs in the picture. The node with the network problem gets evicted by placing the Poison Pill into the Voting File for node1. cssd of node1 will commit suicide now and leave the cluster:
Now in case of a network error, a Split-Brain problem would occur – without a Voting Disk. Suppose node1 has lost the network connection to the Interconnect. In order to prevent that, redundant network cards are recommended since a long time. We introduced HAIP in 11.2.0.2 to make that easier to implement, without the need of bonding, by the way. But here, node1 cannot use the Interconnect anymore. It can still access the Voting Disk, though. Nodes 2 and 3 see their heartbeats still but no longer node1, which is indicated by the green Vs and red fs in the picture. The node with the network problem gets evicted by placing the Poison Pill into the Voting File for node1. cssd of node1 will commit suicide now and leave the cluster:
 The pictures in this posting are almost identical with what I paint on the whiteboard during the course. Hope you find it useful 🙂
The pictures in this posting are almost identical with what I paint on the whiteboard during the course. Hope you find it useful 🙂
Related posting: Voting Disk and OCR in 11gR2: Some changes


#1 von Anju Garg am September 20, 2013 - 16:34
Here is a related post:http://oracleinaction.com/voting-disk/
#2 von Ramesh am September 25, 2013 - 13:11
Thanks for voting disk concept.I always prefer your blog .Thanks you very much for all the concepts.
I have one question here.Who will put poison pill in the voting file.and also please post article on split brain concept.It would be helpful for me.
Thank you sir once again
Thanks
Ramesh D
#3 von John am November 4, 2013 - 14:11
Hi,
What would happen in the scenario of a 3 node RAC with 3 voting disks and the interconnect for each node goes down?
If each node can still see the voting disks but not each other how is it decided which node(s) to evict?
What are the rules for the number of voting disks for RAC’s with more than 2 nodes?
Many thanks,
John
#4 von Uwe Hesse am November 8, 2013 - 12:33
Ramesh D, thank you for the nice feedback! One of the nodes of the majority places the poison pill. We have no split brain concept because the voting disk technique avoids it – not much to post about 🙂
#5 von Uwe Hesse am November 8, 2013 - 12:40
John, there is no relation between the number of RAC nodes and the number of voting disks (except for Extended RAC, where you will have 1 on each side and 1 separately in the middle).
If the interconnect goes down completely, the Master Node will survive and the others get evicted. It is important to keep in mind that the voting disk (regardless of the number of files) as a logical entity is still accessible while the Interconnect has issues.
It provides a second communication path for the nodes if the network fails, that’s the point of it.
#6 von Apostolos am Februar 10, 2014 - 17:34
Hello Uwe,
Thank you for sharing this with us.
Would it be possible to clarify your sentence: „It can still access the Voting Disk, though.“. What do you mean by „access“ and *how* it can access the Voting Disk? Please correct me if I am wrong, but to my understanding the Interconnect network and the network that accesses the shared storage (including the voting disk, should be 2 different networks (2 distinct network infrastructures; cabling, switches, IP network etc). If the shared storage (that stores the voting disk) is on the same network as the private interconnect then what is the point of having a voting disk in the first place. Am I correct? Would you consider it to be a „best practice“ to have 2 distinct networks; one for the interconnect and one for the storage? Finally, does the Interconnect network requires direct access to the shared storage (where the datafiles are stored). To my understanding, it would be a valid configuration to have the Interconnect only for the network hearbeat and Cache Fusion and the storage network (different cabling/IP network) for the disk heartbeat and for accessing the datafiles.
I hope my questions were clear to you.
Thank you very much,
Apostolos
#7 von Uwe Hesse am Februar 10, 2014 - 18:01
Apostolos, yes, the connection to the shared storage will usually be over a different network than the one the interconnect uses. That is why it is often called ‚private interconnect‘. It would be a serious design mistake to have both the shared storage and the interconnect running over the same network if that network has no built-in redundancy to safeguard against single-point of failures.
#8 von Apostolos am Februar 10, 2014 - 18:15
Hello Uew,
Thank you for your lighting reply.
But, even with build-in redundancy in place (for example team bonding, redundant switches, etc) having the disk heartbeat over the same network that the network heartbeat uses, it defeats the purpose of the voting disk. Am I correct? The V.D. is there to inform the surving nodes that the network connectivity failed for one (or more) nodes. If they share the same network and if that network fails for a node, both the network hearbeat and the diskbeat stop transmitting at the same time. So, the failed node will never receive the „poison pill“. Therefore, even with redundancy in place, to my understanding the private interconnect and the storage network should always be on different networks (i.e. network infrastructure)
Also, since such configuration is feasible and supported by Oracle, how does G.I./RAC knows which network to use for accessing the data files (and for the disk heartbeat) and which network to use for Cache Fusion and network heartbeat? I mean that during the G.I. installation you can only differentiate between public, private (interconnect) and „do not use“. There is no distinction between Interconnect and Storage network.
Final question, can the private Interconnect and the storage network be on different IP networks (or subnets)?
Your answers are highly appreciated.
Many thanks,
Apostolos
#9 von Uwe Hesse am Februar 11, 2014 - 15:37
Apostolos, the connection to the shared storage is an OS layer thing that is transparent to the Grid Infrastructure. Therefore no choice with the OUI. In general, you are right with the concept of having a separate network for both – only that we don’t do that ourselves with Exadata, where we use the same (highly redundant Infiniband) network for both 🙂
#10 von Apostolos am Februar 11, 2014 - 15:55
Uwe, thank you very much for your answers and valuable clarifications.
Looking forward to your presentations at the OUG Ireland, which I will also attend.
#11 von aiden am Oktober 28, 2014 - 04:23
Thank you for your useful article.
but I have a queation.
Your article seem to explain that information about network heartbeat (via interconnect) is recordedd on voting disk. Is it right to record network heartbeat on voting disk?
When I read the article in below URL.
„http://orainternals.wordpress.com/2010/10/29/whats-in-a-voting-disk/“
I think such information is not stored on voting disk. I am a little bit confused.
Could you answer my question?
#12 von Uwe Hesse am November 3, 2014 - 12:26
Aiden, we use both, the interconnect and the voting disk to send heartbeats:
CSS is the service that determines which nodes in the cluster are available and provides
cluster group membership and simple locking services to other processes. CSS typically
determines node availability via communication through a dedicated private network with a
voting disk used as a secondary communication mechanism. This is done by sending
heartbeat messages through the network and the voting disk.
The voting disk is a file on a clustered file system that is accessible to all nodes in the cluster.
Its primary purpose is to help in situations where the private network communication fails. The voting disk
is then used to communicate the node state information used to determine which nodes go offline.
#13 von Chris Godfrey (@cg0dfrey) am Januar 28, 2015 - 14:12
Great article, really clearly explains what the Voting Disk actually ‚does‘ rather than just it’s responsibilities.
#14 von Deepak am Juli 16, 2015 - 07:12
thanks for these stuff…but why we require Odd no of v disks
#15 von Uwe Hesse am Juli 21, 2015 - 10:42
Imagine you would have only two voting disks, then one gets corrupted. Which one is valid? See the point? 😉
#16 von Phong Kieu am März 31, 2016 - 12:02
Please explain more detail about the Poison Pill. Which process on which node do that ? Thanks
#17 von Phong Kieu am April 1, 2016 - 08:35
Please help me to clarify about the Poison Pill. Which process of which node put the Poison Pill in the voting files ? I have seen your reply upper, but I do not clear. Thanks.
#18 von Uwe Hesse am April 6, 2016 - 12:11
Phong, I think it is the css process of the master node of the new (smaller) cluster who puts the poison pill into the voting disk.
#19 von santosh am Juni 22, 2016 - 06:35
Is there any sql query to find the status of the Voting disk
Thank you
#20 von sathish kumar dina jothi am Mai 26, 2017 - 19:55
Does the 3 voting disk get info in same time from the nodes or it will be asynchronus? All voting disk contain similar info? suppose if I have 4 nodes and 3 voting disk which node will access which voting disk?
Thank you
Sathish