Beiträge getaggt mit Data Guard
Using Flashback in a Data Guard Environment
If Logical Mistakes happen, we can address them with the Flashback techniques, introduced in Oracle Database 10g already, even if in an Data Guard Environment. In case of „Flashback Table To Timestamp“ or „Flashback Table To Before Drop“, there is nothing special to take into account regarding the Standby Database. It will simply replicate these actions accordingly.
If we do „Flashback Database“ instead, that needs a special treatment of the Standby Database. This posting is designed to show you how to do that:
DGMGRL> show configuration
Configuration
Name: mycf
Enabled: YES
Protection Mode: MaxAvailability
Databases:
prima - Primary database
physt - Physical standby database
Fast-Start Failover: DISABLED
Current status for "mycf":
SUCCESS
This is an 11g Database, but the shown technique should work the same with 10g also. Prima & Physt are both creating Flashback Logs:
SQL> connect sys/oracle@prima as sysdba
Connected.
SQL> select database_role,flashback_on from v$database;
DATABASE_ROLE FLASHBACK_ON
---------------- ------------------
PRIMARY YES
SQL> connect sys/oracle@physt as sysdba
Connected.
SQL> select database_role,flashback_on from v$database;
DATABASE_ROLE FLASHBACK_ON
---------------- ------------------
PHYSICAL STANDBY YES
I will now introduce the „Logical Mistake“ on the Primary Database:
SQL> select * from scott.dept;
DEPTNO DNAME LOC
---------- -------------- -------------
10 ACCOUNTING NEW YORK
20 RESEARCH DALLAS
30 SALES CHICAGO
40 OPERATIONS BOSTON
SQL> drop user scott cascade;
User dropped.
The Redo Protocol gets transmitted with SYNC to the Standby Database and is applied there with Real-Time Apply. In other words: The Logical Mistake has already reached the Standby Database. We could have configured a Delay in the Apply there to address such scenarios. But that is somewhat „old fashioned“; the modern way is to go with flashback. The background behind that is, that in case of a Disaster, hitting the Primary Site, a Delay would cause a longer Failover time. I will now flashback the Primary to get back Scott:
SQL> shutdown immediate
Database closed.
Database dismounted.
ORACLE instance shut down.
SQL> startup mount
ORACLE instance started.
Total System Global Area 313860096 bytes
Fixed Size 1299624 bytes
Variable Size 230689624 bytes
Database Buffers 75497472 bytes
Redo Buffers 6373376 bytes
Database mounted.
SQL> flashback database to timestamp systimestamp - interval '15' minute;
Flashback complete.
SQL> alter database open resetlogs;
Database altered.
SQL> select * from scott.dept;
DEPTNO DNAME LOC
---------- -------------- -------------
10 ACCOUNTING NEW YORK
20 RESEARCH DALLAS
30 SALES CHICAGO
40 OPERATIONS BOSTON
There he is again! Until now, that was not different from a Flashback Database Operation without Data Guard. But now my Standby Database is no longer able to do Redo Apply, because it is „in the future of the Primary Database“. We are in step 2) of the below picture now that I added to illustrate the situation.
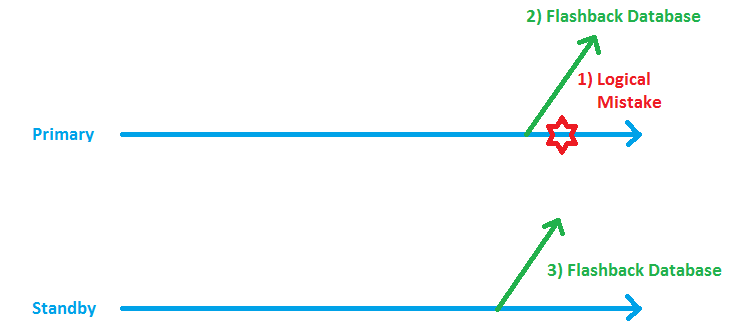
Now I need to put the Standby it into a time, shortly before the present time of the Primary, in order to restart the Redo Apply successfully:
DGMGRL> show configuration
Configuration
Name: mycf
Enabled: YES
Protection Mode: MaxAvailability
Databases:
prima - Primary database
physt - Physical standby database
Fast-Start Failover: DISABLED
Current status for "mycf":
Warning: ORA-16607: one or more databases have failed
DGMGRL> show database physt statusreport
STATUS REPORT
INSTANCE_NAME SEVERITY ERROR_TEXT
* ERROR ORA-16700: the standby database has diverged
from the primary database
* ERROR ORA-16766: Redo Apply is stopped
Please notice that the show statusreport clause is a new feature of 11g. In 10g, you need to look into the Broker Logfile to retrieve that problem.
SQL> connect sys/oracle@prima as sysdba Connected. SQL> select resetlogs_change# from v$database;
RESETLOGS_CHANGE#
-----------------
294223
SQL> connect sys/oracle@physt as sysdba
Connected.
SQL> flashback database to scn 294221;
Flashback complete.
I subtracted 2 from the Resetlogs Change No. above to make sure that we get the Standby close before the present time of the Primary. Now we need to restart the Redo Apply again:
DGMGRL> show configuration
Configuration
Name: mycf
Enabled: YES
Protection Mode: MaxAvailability
Databases:
prima - Primary database
physt - Physical standby database
Fast-Start Failover: DISABLED
Current status for "mycf":
Warning: ORA-16607: one or more databases have failed
DGMGRL> edit database physt set state=apply-on;
Succeeded.
DGMGRL> show configuration
Configuration
Name: mycf
Enabled: YES
Protection Mode: MaxAvailability
Databases:
prima - Primary database
physt - Physical standby database
Fast-Start Failover: DISABLED
Current status for "mycf":
SUCCESS
That was it!
Conclusion: Flashback is the natural counterpart of Real-Time Apply. You can address Logical Mistakes easily with it and you do not need to Delay the actualization of the Standby Database.
My book about Oracle HA, especially Data Guard is published
Added a page that refers to it.
Performance Impact of Logical Standby on the Primary
Implementing High Availabilty for an Oracle Database may impact the performance of the protected Database, depending on the method used. If Data Guard is used, the two protection levels Maximum Availability and Maximum Protection may impact performance of the Primary, as discussed for example in SMITH, MICHAEL T. (2007): Data Guard Redo Transport and Network Best Practices: Oracle Database 10g Release 2, available on OTN.
A special case is the use of a Logical Standby Database, because there is an additional possible Performance Impact, regardless of the protection level: Because the actualization of the Logical Standby is done with SQL Apply, more Redo is generated on the Primary to enable the retrievement of the changed rows on the Standby. With Physical Standby, that is not necessary, because the ROWID recorded on the Primary is the same on the Standby. But on Logical Standby Databases, rows can reside in completely different blocks, so the ROWID from the Primary is meaningless.
Therefore, with Logical Standby present, at least additionally the Primary Key resp. a Unique Column of rows, modified on the Primary Database is recorded. If there is no Primary Key on the table where rows where modified, we record all columns additionally. So depending on the number of columns and the absence of Primary Keys resp. Unique Columns on the production system, a Logical Standby may significantly impact the performance of the Primary Database. Fortunately, we can test that easily before we actually implement a Logical Standby – this posting is designed to show how to do that.
First, we prepare a table without Primary/Unique Columns and relatively many columns:
SQL> drop user adam cascade; grant dba to adam identified by adam; connect adam/adam@prima create table sales as select rownum as id, mod(rownum,5) as channel_id, mod(rownum,1000) as cust_id, 5000 as amount_sold, sysdate as time_id, 'AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA' as col1, 'AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA' as col2, 'AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA' as col3, 'AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA' as col4, 'AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA' as col5, 'AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA' as col6, 'AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA' as col7, 'AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA' as col8, 'AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA' as col9, 'AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA' as col10, 'AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA' as col11, 'AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA' as col12, 'AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA' as col13, 'AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA' as col14, 'AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA' as col15, 'AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA' as col16, 'AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA' as col17, 'AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA' as col18, 'AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA' as col19, 'AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA' as col20 from dual connect by level<=2e5;
That created a table with 200.000 rows and 176 MB in size. We will now record statistics under normal circumstances when no Logical Standby is present.
SQL> exec dbms_workload_repository.create_snapshot
update sales set amount_sold=amount_sold-1;
commit;
exec dbms_workload_repository.create_snapshot
@?/rdbms/admin/awrrpt
The update above took about 27 seconds to complete. We look now at two sections of the AWR-Report:


Elapsed Time was 0.86 minutes, DB Time 0.54 minutes, LGWR wrote 113 MB during that period. There is nothing special with these numbers, they only become meaningful by comparison. Now we setup supplemental log data as if there would be a Logical Standby Database present that would need it. If you are on 11g, the creation of a Logical Standby Database automatically turns on Supplemental Logging (You can spot this by looking at the alert logfile of the Primary during creation of the Logical Standby or by looking at v$database).
SQL> alter database add supplemental log data
(primary key, unique index) columns;
exec dbms_workload_repository.create_snapshot
update sales set amount_sold=amount_sold-1;
commit;
exec dbms_workload_repository.create_snapshot @?/rdbms/admin/awrrpt
alter database drop supplemental log data
(primary key, unique index) columns;
The very same update as before now took about 45 seconds. If we look at the same AWR-sections as before, we can see why:


Elapsed Time increased to 1.18 minutes, DB Time increased to 0.78 minutes, LGWR had to write 249 MB now – more than doubled as before! Of course, the impact is artificially high in this example, but you can see how easy this can be tested before a Logical Standby was actually created. Although this demonstration here was with 11g Release 2, it can be done in the same way with lower versions also.
Pickleball spielen auf YouTube


