If Logical Mistakes happen, we can address them with the Flashback techniques, introduced in Oracle Database 10g already, even if in an Data Guard Environment. In case of „Flashback Table To Timestamp“ or „Flashback Table To Before Drop“, there is nothing special to take into account regarding the Standby Database. It will simply replicate these actions accordingly.
If we do „Flashback Database“ instead, that needs a special treatment of the Standby Database. This posting is designed to show you how to do that:
DGMGRL> show configuration
Configuration
Name: mycf
Enabled: YES
Protection Mode: MaxAvailability
Databases:
prima - Primary database
physt - Physical standby database
Fast-Start Failover: DISABLED
Current status for "mycf":
SUCCESS
This is an 11g Database, but the shown technique should work the same with 10g also. Prima & Physt are both creating Flashback Logs:
SQL> connect sys/oracle@prima as sysdba
Connected.
SQL> select database_role,flashback_on from v$database;
DATABASE_ROLE FLASHBACK_ON
---------------- ------------------
PRIMARY YES
SQL> connect sys/oracle@physt as sysdba
Connected.
SQL> select database_role,flashback_on from v$database;
DATABASE_ROLE FLASHBACK_ON
---------------- ------------------
PHYSICAL STANDBY YES
I will now introduce the „Logical Mistake“ on the Primary Database:
SQL> select * from scott.dept;
DEPTNO DNAME LOC
---------- -------------- -------------
10 ACCOUNTING NEW YORK
20 RESEARCH DALLAS
30 SALES CHICAGO
40 OPERATIONS BOSTON
SQL> drop user scott cascade;
User dropped.
The Redo Protocol gets transmitted with SYNC to the Standby Database and is applied there with Real-Time Apply. In other words: The Logical Mistake has already reached the Standby Database. We could have configured a Delay in the Apply there to address such scenarios. But that is somewhat „old fashioned“; the modern way is to go with flashback. The background behind that is, that in case of a Disaster, hitting the Primary Site, a Delay would cause a longer Failover time. I will now flashback the Primary to get back Scott:
SQL> shutdown immediate
Database closed.
Database dismounted.
ORACLE instance shut down.
SQL> startup mount
ORACLE instance started.
Total System Global Area 313860096 bytes
Fixed Size 1299624 bytes
Variable Size 230689624 bytes
Database Buffers 75497472 bytes
Redo Buffers 6373376 bytes
Database mounted.
SQL> flashback database to timestamp systimestamp - interval '15' minute;
Flashback complete.
SQL> alter database open resetlogs;
Database altered.
SQL> select * from scott.dept;
DEPTNO DNAME LOC
---------- -------------- -------------
10 ACCOUNTING NEW YORK
20 RESEARCH DALLAS
30 SALES CHICAGO
40 OPERATIONS BOSTON
There he is again! Until now, that was not different from a Flashback Database Operation without Data Guard. But now my Standby Database is no longer able to do Redo Apply, because it is „in the future of the Primary Database“. We are in step 2) of the below picture now that I added to illustrate the situation.
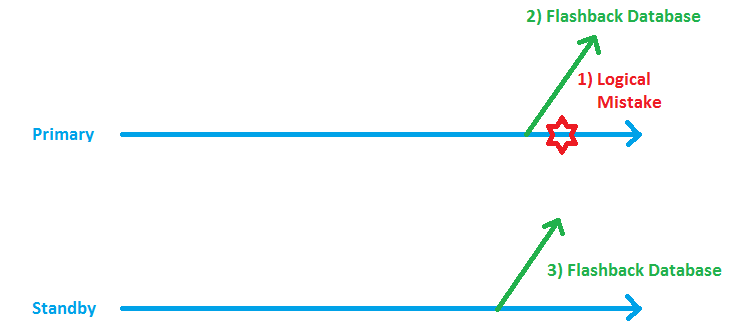
Now I need to put the Standby it into a time, shortly before the present time of the Primary, in order to restart the Redo Apply successfully:
DGMGRL> show configuration
Configuration
Name: mycf
Enabled: YES
Protection Mode: MaxAvailability
Databases:
prima - Primary database
physt - Physical standby database
Fast-Start Failover: DISABLED
Current status for "mycf":
Warning: ORA-16607: one or more databases have failed
DGMGRL> show database physt statusreport
STATUS REPORT
INSTANCE_NAME SEVERITY ERROR_TEXT
* ERROR ORA-16700: the standby database has diverged
from the primary database
* ERROR ORA-16766: Redo Apply is stopped
Please notice that the show statusreport clause is a new feature of 11g. In 10g, you need to look into the Broker Logfile to retrieve that problem.
SQL> connect sys/oracle@prima as sysdba Connected. SQL> select resetlogs_change# from v$database;
RESETLOGS_CHANGE#
-----------------
294223
SQL> connect sys/oracle@physt as sysdba
Connected.
SQL> flashback database to scn 294221;
Flashback complete.
I subtracted 2 from the Resetlogs Change No. above to make sure that we get the Standby close before the present time of the Primary. Now we need to restart the Redo Apply again:
DGMGRL> show configuration
Configuration
Name: mycf
Enabled: YES
Protection Mode: MaxAvailability
Databases:
prima - Primary database
physt - Physical standby database
Fast-Start Failover: DISABLED
Current status for "mycf":
Warning: ORA-16607: one or more databases have failed
DGMGRL> edit database physt set state=apply-on;
Succeeded.
DGMGRL> show configuration
Configuration
Name: mycf
Enabled: YES
Protection Mode: MaxAvailability
Databases:
prima - Primary database
physt - Physical standby database
Fast-Start Failover: DISABLED
Current status for "mycf":
SUCCESS
That was it!
Conclusion: Flashback is the natural counterpart of Real-Time Apply. You can address Logical Mistakes easily with it and you do not need to Delay the actualization of the Standby Database.


#1 von Kamran Agayev A. am August 6, 2010 - 13:49
Nice article Uwe. Thanks for sharing!
#2 von Emre Baransel am August 6, 2010 - 13:59
Hi Uwe,
It’s a good point that delay configuration in dataguard is old-fashioned. Just necessary disk space (FRA) will be enough to benefit from „flashback on“.
Thanks for the useful post!
#3 von Mohamed Azar am August 6, 2010 - 14:00
Nice article Mr.Uwe. Thanks for sharing !!!
#4 von Uwe Hesse am August 6, 2010 - 18:40
Thank you guys for the nice feedback! @Mohamed: Uwe is my first name. You may use it without the Mr. prefix 🙂
#5 von Nitin am August 6, 2010 - 19:30
Thanks Uwe. I enjoy reading your posts !! They are presented well and are easy to understand.
#6 von robinma am August 7, 2010 - 16:24
Nice,Very Thanks for sharing this article
#7 von Marko am August 7, 2010 - 22:14
Thanks for sharing. Very nice written.
Regards!
#8 von Ulfet am August 8, 2010 - 14:02
Hi Uwe, I have read, unfortunately could not implement it. Very very necessary information for DBA. Thank you for sharing.
#9 von jason arneil am August 9, 2010 - 09:34
Hi,
I wonder if a better way of recovering this type of situation, is to actually flashback the standby and extract the required information, as opposed to having to flashback the entire primary copy, and losing transactions that may be of interest.
Though I guess this is just for demonstration purposes only!
jason.
#10 von Uwe Hesse am August 9, 2010 - 09:47
Jason,
yes, that would also be a possible resolution: Just
1) flashback the standby
2) open it READ ONLY
3) export anything lost on the primary
4) Import that to the primary
5) restart standby to MOUNT and let it recover up to the primarys state
But again, there maybe Logical Mistakes that are more complex as my example, where you just cannot take this approach. And finally: Yes, that was for demonstration purpose. But it is not „academically“ 🙂
#11 von lascoltodelvenerdi am August 9, 2010 - 10:00
What you think of using the „retention guarantee“?
In this scenario it would be of help, am I right?
Bye,
Antonio
#12 von PAB am August 9, 2010 - 10:54
Hi Uwe,
Thanks for this excellent articles.
I have one question regarding dataguard.
What steps we have to follow on standby database side after Database Point in time recovery or TSPITR on primary database side?
Thanks
#13 von Uwe Hesse am August 9, 2010 - 11:31
Antonio,
Retention Guarantee is an attribute of an UNDO Tablespace that makes the UNDO_RETENTION specified a directive instead of a wish – wish is default. If you for example set an UNDO_RETENTION=1800, you will be able to do a FLASHBACK QUERY or a FLASHBACK TABLE TO TIMESTAMP for 30 minutes into the past guaranteed. If necessary, new DML is not possible to satisfy this UNDO_RETENTION, if space in the undo tablespace is scarce. In short: Yes, you can address some logical mistakes with that for a guaranteed period of time. There is no explicit relation to Data Guard, though.
PAP,
the steps on the standby are exactly as in the article after a DBPITR on the primary. You need flashback logs on the standby for that also. Else you have to recreate it. I have not thought yet about TSPITR on the primary – should be similar steps as if you create a new tablespace on primary with STANDBY_FILE_MANAGEMENT=MANUAL, I guess.
#14 von Hashmi am August 11, 2010 - 07:48
Very nice demo Sir.
#15 von Unbearable cone-eater am Oktober 18, 2011 - 14:40
That’s what i was looking for! Thanks.
#16 von Alee Raza Memon am Dezember 16, 2013 - 10:15
Sir! Its great. Thanks alottt.
#17 von 5i5i am Juni 15, 2015 - 15:54
Nice article.
Alas when I follow this procedure, I have the problem that after I rollback the standby to an SCN well before the resetlogs, abd then switch on the redo apply again, it always tells me ORA-16700: the standby database has diverged from the primary database.
I’ve even tried removing the standby archived redo logs from the standby so it has to re-fetch them from the primary again, but each time I set apply back on it gives me the same diverged message.
#18 von Uwe Hesse am Juni 30, 2015 - 07:11
It works normally exactly as in the article described, so I can only guess that you didn’t flashback the standby far enough or that you flashed back to another incarnation. Try using the resetlogs_change# – 2 like I’ve showed above.
#19 von chetan032014 am Juli 1, 2015 - 17:38
Very nice article, I implemented and it worked perfect !!
I have another scenario, where I don’t have broker implemented. I have only physical standby setup with flashback enabled only on Primary.
Is there a way I can sync my standby without rebuilding after I flashback primary to a restore point ?
#20 von Detlef Färber am Mai 17, 2016 - 15:55
Hallo Uwe,
wir haben in einem speziellen Fall das Flashback nach diesem Scenario (mit 2 physical standby) durchgeführt. Die beiden „physical“ Standby sind auf primary-SCN -2 zurückgesetzt und Dataguard ist nach dem „set state=apply-on“ wieder angelaufen.
Im Alert.log der Standby haben wir gesehen, das das Flashback eine neue Inkarnation angelegt und das Recover automatisch mit
ALTER DATABASE RECOVER MANAGED STANDBY DATABASE THROUGH ALL SWITCHOVER DISCONNECT USING CURRENT LOGFILE
wieder gestartet hat.
So weit, so gut.
Allerdings wird jetzt im CloudControl das „Last Applied Log“ [73] immer um 1 weniger als das „Last Received Log” [74] angezeigt.
Bei der Abfrage in V$ARCHIVED_LOG auf der Standby wird die jeweils letzte Sequence jetzt mit APPLIED=NO angezeigt.
Die Abfrage in V$MANAGED_STANDBY zeigt den MRP0-Prozess mit dem Status APPLYING_LOG auf der aktuellen Sequence#.[75].
Nach jedem Log-Switch auf der Primary springt diese Sequence# [74] sofort auf APPLIED=YES, die nun neue, zuletzt empfangene Sequence# geht aber auf APPLIED=NO.
Im MOS DOCID 1481927.1 (und Bug 13114860) haben wir eine ähnlich Situation (allerdings für 11.2.0.3) gefunden, aber keine Lösung oder einen Workaround.
hier noch die DB Beschreibung:
OS : 64-bit Windows Server 2008 R2 Enterprise
DB Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 – 64bit Production
Hast Du einen Gedanken, wo das Problem liegt und ob es einen Workaround gibt.
Mit freundlichen Grüßen, D.Färber
PS: auf der Standby werden in der V$ARCHIVED_LOG und der V$LOG_HISTORY noch „alte“ Sequence# (> 10000) angezeigt,
mit der zugehörigen (und passenden) RESETLOGS_CHANGE# :
RESETLOGS_CHANGE#:1 für die „alten“ und hohen Sequence# ,
RESETLOGS_CHANGE#:292768400 für die „neuen“ und niedrigen Sequence# .
Ev. „denkt“ DataGuard, das es eine Lücke in den Sequence# gibt, und Applied erst, wenn das nächste ArchiveLog übertragen wird ?
#21 von Uwe Hesse am Mai 20, 2016 - 08:43
Detlef, sorry, kann ich nichts Schlaues dazu beitragen. Sicherlich ein Fall für den Support.
#22 von Grzegorz Goryszewski am Dezember 18, 2016 - 14:38
Hi,
can we achive the same with guarantee restore point ? So the standby is not in flashback mode but You do guarantee restore point on it first and the on primary and in case of flashback You can be happy with standby working ?
Regards
GG
#23 von kurschies am Juni 27, 2017 - 13:48
Hello Uwe,
can the same be achieved with the „reinstate database“ command in dgmgrl?
regards
Benjamin
#24 von Uwe Hesse am Juli 3, 2017 - 07:44
Benjamin, no, I don’t think so. Reinstate works only for the particular case of a former primary that is now supposed to act as a standby for the new primary. Like I have described here: https://uhesse.com/2016/09/21/how-to-reinstate-the-old-primary-as-a-standby-after-failover-in-oracle/
#25 von Peter am Dezember 18, 2017 - 13:28
Hi Uwe
in a physical dataguard configuration its necessary/recommendable to configure flashback on the standby database?
Thks
#26 von Uwe Hesse am Dezember 18, 2017 - 21:27
Peter, it is not mandatory to configure flashback for Data Guard configurations but recommended to configure it on both sides, primary and standby.
Some features require it: The ability to reinstate depends on it and Fast-Start Failover has it as a prerequisite.
#27 von Amy am Mai 22, 2018 - 00:59
Uwe:
Thank you for sharing! If I have GRP turned on the primary and flashback on the standby without GRP. I deleted archivelogs and flashback logs are gone in the standby. Assuming 1 week later, I have to tflashback the primary to GRP, can I still flashback the standby to „primary scn-2“ without archivelogs and flashback logs on standby? Standby can fetch archivelogs from primary but I am not aware it can do the same with flashback logs. Thanks!
#28 von Uwe Hesse am Mai 22, 2018 - 09:38
Amy, I don’t think that flashback database will work on the standby without flashback logs even if they are present on the primary. But that’s just a guess, didn’t try that yet. Maybe I check that if I find some time. Or you do it and come back to tell us here 🙂