Beiträge getaggt mit Exasol
New free online course: #Exasol Virtual Schemas
Virtual Schemas integrate foreign data sources into the Exasol database. They enable Exasol to become the central source of truth in your data warehouse landscape.
We added another free online learning course to our curriculum that explains how to deal with Virtual Schemas. Like the others, it comes with many hands-on practices to support a good learning experience. It also contains many demo videos like this one:
I recorded this clip (like most of the others) myself, but this time we decided to do a voice-over by native professional speakers.
Certification exams are free, also for this new course. When you complete the majority of hands-on labs in the course, you get one free certification exam granted per person and per course.
What are you waiting for? Come and get it!
Elevate your IT career with free certifications from #Exasol!

Exasol is the fastest analytics database. It is rapidly spreading worldwide. Exasol knowledge is in high demand therefore. You can get it for free from us here: training.exasol.com
We provide free online learning courses to cope with our rapid growth – these scale better than instructor-led training. Our courses are short and to-the-point: Exasol doesn’t need extensive training because it’s easy to work with. It delivers outstanding performance with very low maintenance. Our database is designed to take care of itself to a large degree. That’s why each of our few courses can be completed within one day.
Exasol certification exams are charged with 150 Euro per attempt. We decided now to grant one free attempt per course. For you, that means you can get fully Exasol certified for free – if you prepare well for the exams.
Good luck with that, we love to see you succeed 🙂
Some feedback we got from attendees:
„I liked the training very much. It was clearly structured, easy to follow and very interesting. I liked the quizzes and hands-on. Very good job.“
„With over 9 years of experience in Oracle technologies, Exasol was quite new for me but the precise course content and availability of Community Edition of Exasol made learning smooth.“
„Thank you #Exasol for offering free high-quality courses!“
„It was insightful to go deep into Exasol database architecture and perceive what makes Exasol world’s fastest analytics database. Kudos to the Exacademy team for awesome training content.“
„Thank you Exasol for offering this great (free!) training experience!“
„I enjoyed exploring distributed in-memory database Exasol. I liked comprehensive auto-tuning features those reduces maintenance hassles and let you focus on Analytics. It was a great learning experience, and I got the chance to sharpen distributed design skills and pick up a few new ones along the way.“
„Did Exasol Certified Associate!!! Great Experience… Thanks Exasol!“
„Successfully completed ‚Exasol 6 Certified Professional Administrator‘. Proud to be an Exasol Certified Professional!! It was a great learning journey.“
„This time, I was learning about #Exasol – the high-performance, cloud-first analytics database. Why? Well, got the idea from my colleague, who did it first, and I thought – why not… it’s an opportunity to learn something new! It was fun learning, going through the nice material and especially doing the hands-on labs.“
Run #Python directly in the database

With Python integrated to the database, you can utilize the power of SQL together with one of the most popular programming languages. And you run the program where the data is: Inside the database. Instead of having to bring the data to the program.
The Exasol database integrates the popular programming languages Python, Java and R as UDF scripting languages, together with the less known but powerful and elegant programming language Lua.
Let’s look at an example how Python can be used in Exasol, together with SQL:
--/
create or replace python3 scalar script find_books(keyword varchar(2000000)) emits (title varchar(2000000)) as
import urllib.request
import urllib.parse
import json
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
def run(ctx):
with urllib.request.urlopen('https://www.googleapis.com/books/v1/volumes?maxResults=40&q='+ urllib.parse.quote_plus(ctx.keyword)) as url:
s = url.read()
data = json.loads(s)
for item in data["items"]:
ctx.emit(item["volumeInfo"]["title"])
/We’re using the free google api here to access book titles. That script is then called like this:
select find_books('discworld');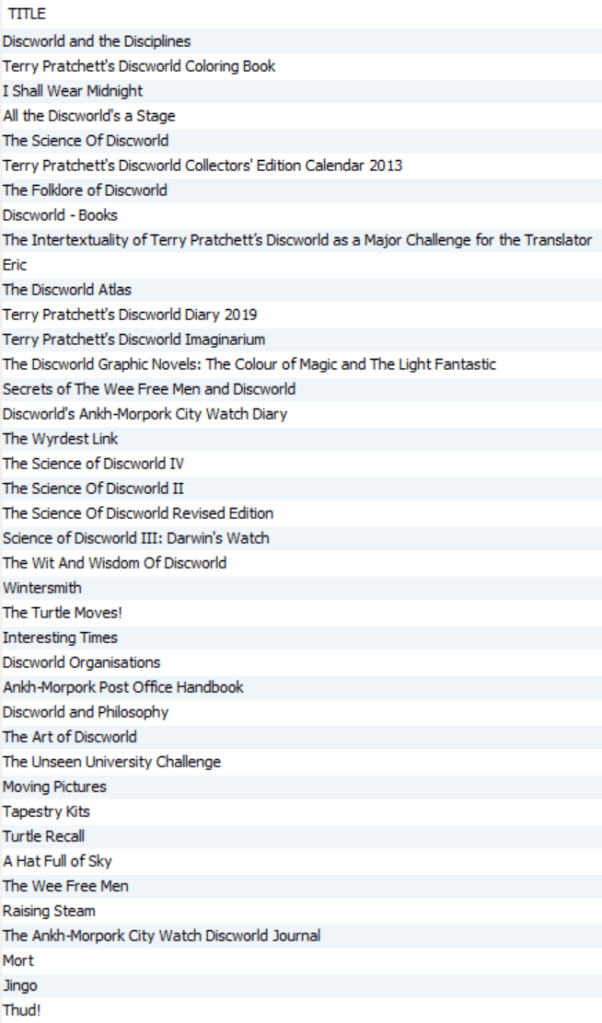
How about sorting that list after length of title? That’s something SQL can do very well:
select length(title), title from (select find_books('discworld')) order by 1;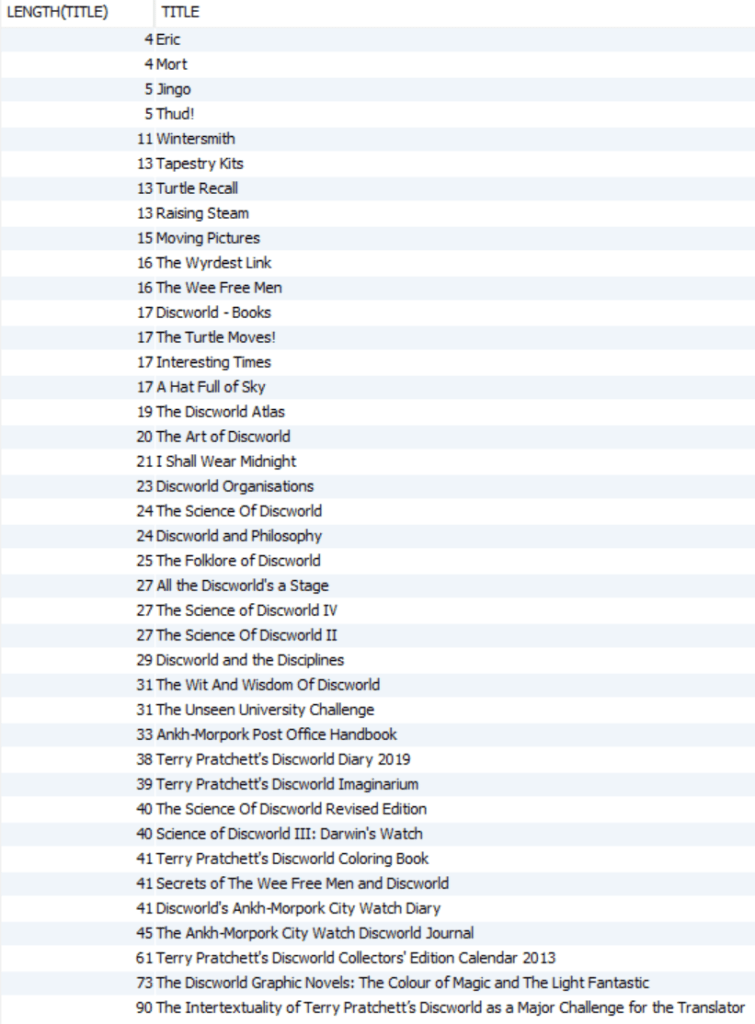
This should give you an idea about the endless and powerful options you have by combining Python with SQL, both integrated in the database.
By the way: We’re happy to educate you on this for free with our online learning course Exasol Advanced Analytics 🙂
Pickleball spielen auf YouTube


