Beiträge getaggt mit flashback
Dealing with Oracle Database Block Corruption

Media errors don’t always destroy files completely. Sometimes, only small parts of the file are damaged respectively corrupted. It may even not be noticed by end users or admins for a while. This article shows how to detect block corruption and recover from it. The demo is done on 11g but the shown techniques work in the same way for 12c also. I have corrupted blocks on my demo database affecting the emp table of the user scott:
SQL> select * from scott.emp;
select * from scott.emp
*
ERROR at line 1:
ORA-01578: ORACLE data block corrupted (file # 4, block # 131)
ORA-01110: data file 4: '/home/oracle/prima/users01.dbf'
This shows that not the whole tablespace is affected:
SQL> select * from scott.dept; DEPTNO DNAME LOC ---------- -------------- ------------- 10 ACCOUNTING NEW YORK 20 RESEARCH DALLAS 30 SALES CHICAGO 40 OPERATIONS BOSTON SQL> select table_name,tablespace_name from dba_tables where owner='SCOTT'; TABLE_NAME TABLESPACE_NAME ------------------------------ ------------------------------ DEPT USERS EMP USERS
Whenever we get these kind of error messages, we need to check all the blocks. Typically, error messages about block corruption come up during an RMAN backup, but I like to defer that a little to show an 11g New Feature before. Checking all blocks now:
RMAN> validate check logical database; Starting validate at 16-NOV-10 using target database control file instead of recovery catalog allocated channel: ORA_DISK_1 channel ORA_DISK_1: SID=107 device type=DISK channel ORA_DISK_1: starting validation of datafile channel ORA_DISK_1: specifying datafile(s) for validation input datafile file number=00001 name=/home/oracle/prima/system01.dbf input datafile file number=00002 name=/home/oracle/prima/sysaux01.dbf input datafile file number=00003 name=/home/oracle/prima/undotbs01.dbf input datafile file number=00004 name=/home/oracle/prima/users01.dbf channel ORA_DISK_1: validation complete, elapsed time: 00:00:01 List of Datafiles ================= File Status Marked Corrupt Empty Blocks Blocks Examined High SCN ---- ------ -------------- ------------ --------------- ---------- 1 OK 0 17594 38400 277491 File Name: /home/oracle/prima/system01.dbf Block Type Blocks Failing Blocks Processed ---------- -------------- ---------------- Data 0 13854 Index 0 4487 Other 0 2465 File Status Marked Corrupt Empty Blocks Blocks Examined High SCN ---- ------ -------------- ------------ --------------- ---------- 2 OK 0 20381 25600 277631 File Name: /home/oracle/prima/sysaux01.dbf Block Type Blocks Failing Blocks Processed ---------- -------------- ---------------- Data 0 869 Index 0 957 Other 0 3393 File Status Marked Corrupt Empty Blocks Blocks Examined High SCN ---- ------ -------------- ------------ --------------- ---------- 3 OK 0 541 22784 277631 File Name: /home/oracle/prima/undotbs01.dbf Block Type Blocks Failing Blocks Processed ---------- -------------- ---------------- Data 0 0 Index 0 0 Other 0 22243 File Status Marked Corrupt Empty Blocks Blocks Examined High SCN ---- ------ -------------- ------------ --------------- ---------- 4 FAILED 0 1133 1280 271968 File Name: /home/oracle/prima/users01.dbf Block Type Blocks Failing Blocks Processed ---------- -------------- ---------------- Data 0 10 Index 0 0 Other 1 137 validate found one or more corrupt blocks See trace file /home/oracle/prima/diag/rdbms/prima/prima/trace/prima_ora_18316.trc for details channel ORA_DISK_1: starting validation of datafile channel ORA_DISK_1: specifying datafile(s) for validation including current control file for validation including current SPFILE in backup set channel ORA_DISK_1: validation complete, elapsed time: 00:00:01 List of Control File and SPFILE =============================== File Type Status Blocks Failing Blocks Examined ------------ ------ -------------- --------------- SPFILE OK 0 2 Control File OK 0 612 Finished validate at 16-NOV-10
We have already a couple of 11g New Features here: The syntax has changed from backup validate (since 9i) to just validate (11g) – probably to make clear that this does not perform a backup but a check of corrupted blocks instead. Before 11g, the command did not show the verbose list of checked respectively corrupted blocks like we see above.
The addition check logical will also check for logical block corruption, which is not done by default.
Checking all the blocks here is more efficient than doing an immediate recovery of the one block mentioned in the error message above. There may be many more not spotted yet. Same is true for an ordinary backup that would interrupt at the first spotted corrupted block as we will see later on.
The validate command populated the view v$database_block_corruption, that is now internally read by RMAN in order to repair all the found corrupted blocks. The next 11g New Feature here is: It will take the block out of the Flashback Logs, if present there!
RMAN> blockrecover corruption list; Starting recover at 16-NOV-10 using channel ORA_DISK_1 searching flashback logs for block images finished flashback log search, restored 1 blocks starting media recovery media recovery complete, elapsed time: 00:00:01 Finished recover at 16-NOV-10
I was so bold that I did not even take a backup before – to make sure this new feature must be used:
RMAN> list backup; specification does not match any backup in the repository
I’m going to take a backup now, but before that, I cause again block corruption. So we will see that RMAN stops at the first noticed corrupted block. No Third-Party-Tool would recognize the block corruption, BTW, so we have another reason to actually use RMAN here. If we say backup check logical database instead of just backup database, RMAN will also check for logical block corruption during the backup.
[oracle@uhesse-pc skripte]$ rman target sys/oracle@prima
Recovery Manager: Release 11.2.0.2.0 - Production on Tue Nov 16 15:22:14 2010
Copyright (c) 1982, 2009, Oracle and/or its affiliates. All rights reserved.
connected to target database: PRIMA (DBID=1967518488)
RMAN> backup database;
Starting backup at 16-NOV-10
using target database control file instead of recovery catalog
allocated channel: ORA_DISK_1
channel ORA_DISK_1: SID=110 device type=DISK
channel ORA_DISK_1: starting full datafile backup set
channel ORA_DISK_1: specifying datafile(s) in backup set
input datafile file number=00001 name=/home/oracle/prima/system01.dbf
input datafile file number=00002 name=/home/oracle/prima/sysaux01.dbf
input datafile file number=00003 name=/home/oracle/prima/undotbs01.dbf
input datafile file number=00004 name=/home/oracle/prima/users01.dbf
channel ORA_DISK_1: starting piece 1 at 16-NOV-10
RMAN-03009: failure of backup command on ORA_DISK_1 channel at 11/16/2010 15:22:22
ORA-19566: exceeded limit of 0 corrupt blocks for file /home/oracle/prima/users01.dbf
continuing other job steps, job failed will not be re-run
channel ORA_DISK_1: starting full datafile backup set
channel ORA_DISK_1: specifying datafile(s) in backup set
including current control file in backup set
including current SPFILE in backup set
channel ORA_DISK_1: starting piece 1 at 16-NOV-10
channel ORA_DISK_1: finished piece 1 at 16-NOV-10
piece handle=/home/oracle/flashback/PRIMA/backupset/2010_11_16/o1_mf_ncsnf_TAG20101116T152221_6g54wzkb_.bkp tag=TAG20101116T152221 comment=NONE
channel ORA_DISK_1: backup set complete, elapsed time: 00:00:01
RMAN-00571: ===========================================================
RMAN-00569: =============== ERROR MESSAGE STACK FOLLOWS ===============
RMAN-00571: ===========================================================
RMAN-03009: failure of backup command on ORA_DISK_1 channel at 11/16/2010 15:22:22
ORA-19566: exceeded limit of 0 corrupt blocks for file /home/oracle/prima/users01.dbf
Again the same sequence as above validate check logical database & blockrecover corruption list will solve the problem. During the whole process, the users tablespace remains online and usable, except the emp table of scott.
Conclusion: We have a powerful tool with RMAN to spot and repair corrupted blocks by using intact versions of the corrupted blocks from backup (since 9i already) or even from Flashback Logs (since 11g) – which is probably faster – while keeping up the availability of the affected tablespace.
Using Flashback in a Data Guard Environment
If Logical Mistakes happen, we can address them with the Flashback techniques, introduced in Oracle Database 10g already, even if in an Data Guard Environment. In case of „Flashback Table To Timestamp“ or „Flashback Table To Before Drop“, there is nothing special to take into account regarding the Standby Database. It will simply replicate these actions accordingly.
If we do „Flashback Database“ instead, that needs a special treatment of the Standby Database. This posting is designed to show you how to do that:
DGMGRL> show configuration
Configuration
Name: mycf
Enabled: YES
Protection Mode: MaxAvailability
Databases:
prima - Primary database
physt - Physical standby database
Fast-Start Failover: DISABLED
Current status for "mycf":
SUCCESS
This is an 11g Database, but the shown technique should work the same with 10g also. Prima & Physt are both creating Flashback Logs:
SQL> connect sys/oracle@prima as sysdba
Connected.
SQL> select database_role,flashback_on from v$database;
DATABASE_ROLE FLASHBACK_ON
---------------- ------------------
PRIMARY YES
SQL> connect sys/oracle@physt as sysdba
Connected.
SQL> select database_role,flashback_on from v$database;
DATABASE_ROLE FLASHBACK_ON
---------------- ------------------
PHYSICAL STANDBY YES
I will now introduce the „Logical Mistake“ on the Primary Database:
SQL> select * from scott.dept;
DEPTNO DNAME LOC
---------- -------------- -------------
10 ACCOUNTING NEW YORK
20 RESEARCH DALLAS
30 SALES CHICAGO
40 OPERATIONS BOSTON
SQL> drop user scott cascade;
User dropped.
The Redo Protocol gets transmitted with SYNC to the Standby Database and is applied there with Real-Time Apply. In other words: The Logical Mistake has already reached the Standby Database. We could have configured a Delay in the Apply there to address such scenarios. But that is somewhat „old fashioned“; the modern way is to go with flashback. The background behind that is, that in case of a Disaster, hitting the Primary Site, a Delay would cause a longer Failover time. I will now flashback the Primary to get back Scott:
SQL> shutdown immediate
Database closed.
Database dismounted.
ORACLE instance shut down.
SQL> startup mount
ORACLE instance started.
Total System Global Area 313860096 bytes
Fixed Size 1299624 bytes
Variable Size 230689624 bytes
Database Buffers 75497472 bytes
Redo Buffers 6373376 bytes
Database mounted.
SQL> flashback database to timestamp systimestamp - interval '15' minute;
Flashback complete.
SQL> alter database open resetlogs;
Database altered.
SQL> select * from scott.dept;
DEPTNO DNAME LOC
---------- -------------- -------------
10 ACCOUNTING NEW YORK
20 RESEARCH DALLAS
30 SALES CHICAGO
40 OPERATIONS BOSTON
There he is again! Until now, that was not different from a Flashback Database Operation without Data Guard. But now my Standby Database is no longer able to do Redo Apply, because it is „in the future of the Primary Database“. We are in step 2) of the below picture now that I added to illustrate the situation.
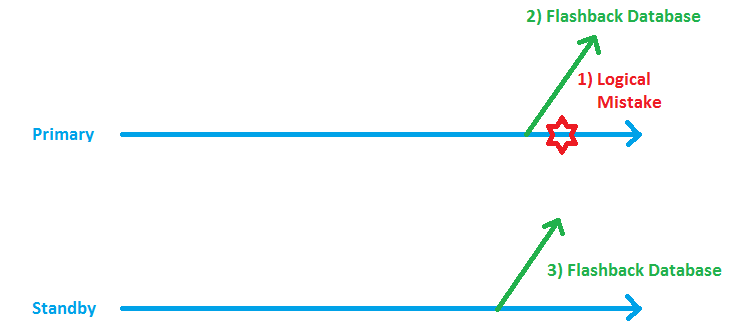
Now I need to put the Standby it into a time, shortly before the present time of the Primary, in order to restart the Redo Apply successfully:
DGMGRL> show configuration
Configuration
Name: mycf
Enabled: YES
Protection Mode: MaxAvailability
Databases:
prima - Primary database
physt - Physical standby database
Fast-Start Failover: DISABLED
Current status for "mycf":
Warning: ORA-16607: one or more databases have failed
DGMGRL> show database physt statusreport
STATUS REPORT
INSTANCE_NAME SEVERITY ERROR_TEXT
* ERROR ORA-16700: the standby database has diverged
from the primary database
* ERROR ORA-16766: Redo Apply is stopped
Please notice that the show statusreport clause is a new feature of 11g. In 10g, you need to look into the Broker Logfile to retrieve that problem.
SQL> connect sys/oracle@prima as sysdba Connected. SQL> select resetlogs_change# from v$database;
RESETLOGS_CHANGE#
-----------------
294223
SQL> connect sys/oracle@physt as sysdba
Connected.
SQL> flashback database to scn 294221;
Flashback complete.
I subtracted 2 from the Resetlogs Change No. above to make sure that we get the Standby close before the present time of the Primary. Now we need to restart the Redo Apply again:
DGMGRL> show configuration
Configuration
Name: mycf
Enabled: YES
Protection Mode: MaxAvailability
Databases:
prima - Primary database
physt - Physical standby database
Fast-Start Failover: DISABLED
Current status for "mycf":
Warning: ORA-16607: one or more databases have failed
DGMGRL> edit database physt set state=apply-on;
Succeeded.
DGMGRL> show configuration
Configuration
Name: mycf
Enabled: YES
Protection Mode: MaxAvailability
Databases:
prima - Primary database
physt - Physical standby database
Fast-Start Failover: DISABLED
Current status for "mycf":
SUCCESS
That was it!
Conclusion: Flashback is the natural counterpart of Real-Time Apply. You can address Logical Mistakes easily with it and you do not need to Delay the actualization of the Standby Database.
Turning Flashback Database on & off with Instance in Status OPEN

Since 11g, you can turn Flashback Database on and off without having to restart the Instance. It can stay in status OPEN, whereas in 10g, you had to go in Status MOUNT to change the Flashback mode, similar as it is still necessary to go to MOUNT in order to change the Archivelog mode.
Here is a short demo on the command line:
SQL> select * from v$version;
BANNER
--------------------------------------------------------------------------------
Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - Production
PL/SQL Release 11.2.0.1.0 - Production
CORE 11.2.0.1.0 Production
TNS for Linux: Version 11.2.0.1.0 - Production
NLSRTL Version 11.2.0.1.0 - Production
SQL> select log_mode,flashback_on from v$database;
LOG_MODE FLASHBACK_ON
------------ ------------------
ARCHIVELOG NO
SQL> select status from v$instance;
STATUS
------------
OPEN
I am already in Archivelog mode, but Flashback (Database) is not turned on yet. Instance is OPEN – and stays there:
SQL> alter database flashback on;
Database altered.
SQL> select log_mode,flashback_on from v$database;
LOG_MODE FLASHBACK_ON
------------ ------------------
ARCHIVELOG YES
SQL> alter database flashback off;
Database altered.
SQL> select log_mode,flashback_on from v$database;
LOG_MODE FLASHBACK_ON
------------ ------------------
ARCHIVELOG NO
Conclusion: If you are about to do a critical operation with your database that you may want to rewind in case, you can turn on Flashback Logging before that operation and turn it off afterwards without limiting the availability of your Database!
Watch me on YouTube explaining the above:
Keep in mind that this affects only your ability to do FLASHBACK DATABASE, not the other forms of Flashback like FLASHBACK QUERY or FLASHBACK TABLE because they do not need Flashback Logs and work regardless of what you see in the column FLASHBACK_ON from V$DATABASE as explained here.
Pickleball spielen auf YouTube


