Beiträge getaggt mit exadata
Modify segment attributes on Logical Standby during Migration
Whenever you want to change certain storage attributes of your production tables, a Logical Standby can help. A common case is to do that during a migration. Not only will Data Guard help you to reduce downtime for the migration to the time it takes to do a switchover! With a Logical Standby, the segments do not need to look exactly (physically) the same as on the Primary. That’s where the name comes from 🙂
[oracle@uhesse1 ~]$ dgmgrl sys/oracle@prima DGMGRL for Linux: Version 11.2.0.3.0 - 64bit Production Copyright (c) 2000, 2009, Oracle. All rights reserved. Welcome to DGMGRL, type "help" for information. Connected. DGMGRL> show configuration Configuration - myconf Protection Mode: MaxPerformance Databases: prima - Primary database logst - Logical standby database Fast-Start Failover: DISABLED Configuration Status: SUCCESS
My demo setup is on 11.2.0.3, but the shown technique should work similar with older versions. I will now create a demo user with a table that gets the default initial extent of 64k in the default tablespace of the database that uses autoallocate as the extent allocation type:
SQL> grant dba to adam identified by adam; Grant succeeded. SQL> connect adam/adam@prima Connected. SQL> create table t as select * from dual; Table created. SQL> select extents,initial_extent from user_segments where segment_name='T'; EXTENTS INITIAL_EXTENT ---------- -------------- 1 65536 SQL> select rowid,t.* from t; ROWID D ------------------ - AAADSaAAEAAAACTAAA X
I listed the rowid above to show that it will be different on the Logical Standby – but that is no problem because of the supplemental logging we do on the Primary to be able to identify the modified rows on the Logical Standby without that rowid from the Primary. Now let’s assume we want to have the initial extent changed to 8M – a recommendation on Exadata for large segments, by the way. See how easy that can be done:
DGMGRL> edit database logst set state=apply-off;
Succeeded.
DGMGRL> show database logst;
Database - logst
Role: LOGICAL STANDBY
Intended State: APPLY-OFF
Transport Lag: 0 seconds
Apply Lag: 0 seconds
Instance(s):
logst
Database Status:
SUCCESS
I need to stop the SQL Apply – not the Redo Transport – before the change on the Logical Standby can be done. Technically speaking, your Recovery Point Objective remains the same as before, but your Recovery Time Objective increases according to the amount of redo that accumulates now in the meantime. Now to the modification of the storage attributes:
SQL> select to_char(event_time,'dd-hh24:mi:ss') as time,event,status from dba_logstdby_events order by 1; TIME EVENT STATUS ----------- -------------------------------------------------- ----------------------------------------------------------- 29-16:03:07 Shutdown acknowledged 29-16:03:07 ORA-16128: User initiated stop apply successfully completed SQL> alter table adam.t move storage (initial 8m); Table altered.
If you see any other error message in dba_logstdby_events, fix these errors before you go on with the task. The table uses now 8M initial extents – it is reorganized also during this step. In my simplified example, there is no index on the table. Otherwise indexes need to be rebuilt now. I will restart the SQL Apply and check whether it works again:
DGMGRL> edit database logst set state=apply-on;
Succeeded.
DGMGRL> show database logst;
Database - logst
Role: LOGICAL STANDBY
Intended State: APPLY-ON
Transport Lag: 0 seconds
Apply Lag: 0 seconds
Instance(s):
logst
Database Status:
SUCCESS
SQL> update t set dummy='Y' where dummy='X';
1 row updated.
SQL> commit;
Commit complete.
Now back on the Logical Standby:
SQL> connect adam/adam@logst Connected. SQL> select to_char(event_time,'dd-hh24:mi:ss') as time,event,status from dba_logstdby_events order by 1; TIME EVENT STATUS ----------- -------------------------------------------------- ------------------------------------------- 29-16:16:11 ORA-16111: log mining and apply setting up 29-16:16:11 Apply LWM 463670, HWM 463670, SCN 464525 29-16:16:11 APPLY_UNSET: MAX_SGA 29-16:16:11 APPLY_UNSET: MAX_SERVERS SQL> select extents,initial_extent from user_segments where segment_name='T'; EXTENTS INITIAL_EXTENT ---------- -------------- 1 8388608 SQL> select rowid,t.* from t; ROWID D ------------------ - AAADZrAAEAAAAESAAA Y
As you can see, the storage attribute was changed, and the rowid is different here. After a switchover to the Logical Standby, my production table uses now 8m initial extents.
Conclusion: With a Logical Standby in place, it is relatively easy to change storage attributes. It requires a stop of the SQL Apply process, though. You may want to use this approach during a migration to combine the major task (the migration) with some housekeeping. If you ever wondered why Logical Standby is listed under the Logical Migration Methods although it starts with (and has the same limitations as) a Physical Standby – you have just seen the reason. As always: Don’t believe it, test it 🙂
Appliance? How #Exadata will impact your IT Organization
The impact, Exadata will have on your IT‘ s organizational structure can range from ‚None at all‘ to ‚Significantly‘. I’ll try to explain which kind of impact will likely be seen under which circumstances. The topic seems to be very important, as it is discussed often in my courses and also internally. First, it is probably useful to be clear about the often used term ‚Appliance‘ in relation to Exadata: I think that term is misleading in so far as Exadata requires ongoing Maintenance & Administration, similar to an ordinary Real Application Cluster. It is not like you deploy it once and then it takes care of itself.
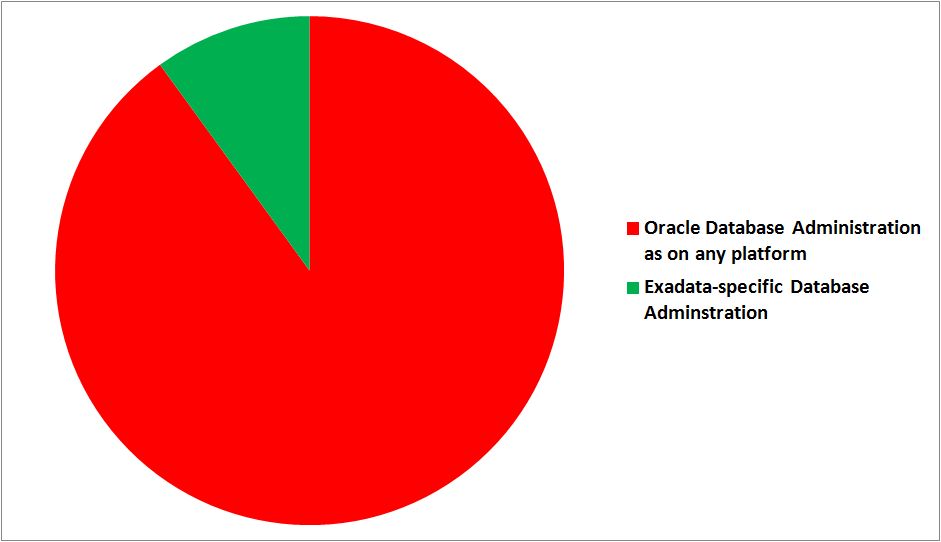
Due to its nature as an Engineered System, it is partly much easier to deploy and to manage than a self-cooked solution, but there are still administrative tasks to do with Exadata, as the following picture shows:
 Without pretending precision (therefore no percentages mentioned), you can see that the major task on Exadata is by far Database Administration, while Storage Administration and System/Network-Administration are the smaller portions. The question is now how this maintenance is done. You could of course decide to let Oracle do it partly or completely – very comfortable, but not the focus of this article. Instead, let’s assume your IT Organization is supposed to manage Exadata.
Without pretending precision (therefore no percentages mentioned), you can see that the major task on Exadata is by far Database Administration, while Storage Administration and System/Network-Administration are the smaller portions. The question is now how this maintenance is done. You could of course decide to let Oracle do it partly or completely – very comfortable, but not the focus of this article. Instead, let’s assume your IT Organization is supposed to manage Exadata.
1. The siloed approach
I think it’s important to emphasize that your internal organization does not have to change because of Exadata. You can stay as you are! Many customers have dedicated and separated teams for Database Administration, Storage Administration and System/Network Administration. It is perfectly valid to decide that the different components of your Exadata are managed by those different teams as on this picture visualized:
 The responsiveness and agility towards business requirements will be the same with the siloed approach as it is presently with other Oracle-related deployments at your site. There is obviously some internal overhead involved, because the different teams need to be coordinated for the Exadata maintenance tasks.
The responsiveness and agility towards business requirements will be the same with the siloed approach as it is presently with other Oracle-related deployments at your site. There is obviously some internal overhead involved, because the different teams need to be coordinated for the Exadata maintenance tasks.
This approach is likely to be seen if Exadata is deployed more for tactical reasons (we put this one critical and customer-facing OLTP system on an Exadata eight-rack, e.g.) respectively if your internal organization is very static and difficult to change. I have seen this from time to time (SysAdmins in the course who have never seen Oracle Databases before), but I would say it is more an exception than the rule.
In short: You will get the technical benefits out of Exadata, but you will leave benefits that come from increased administrative efficiency and agility on the table.
2. The Exadata Database Administration (EDBA) Team approach
Here you give the administrative ownership of Exadata to a team, built largely or exclusively from your DBAs and give them named contacts from the other IT groups, so they can get their expertise on demand, like this picture here shows:
 Why is the DBA team supposed to own Exadata? Because as shown on Pic 1 above, they are doing the major task on Exadata anyways. And it is relatively easy to train these DBAs for Oracle Database Administration on Exadata, because they know already most of it:
Why is the DBA team supposed to own Exadata? Because as shown on Pic 1 above, they are doing the major task on Exadata anyways. And it is relatively easy to train these DBAs for Oracle Database Administration on Exadata, because they know already most of it:
 I simply cannot emphasize enough how important this point is: The know-how of your Oracle DBAs remains completely valid & useful on Exadata! The often huge investment into that know-how keeps paying back! I am still surprised that the true quote ‚Exadata is still Oracle!‘ is from a competitor and not from our Marketing 🙂
I simply cannot emphasize enough how important this point is: The know-how of your Oracle DBAs remains completely valid & useful on Exadata! The often huge investment into that know-how keeps paying back! I am still surprised that the true quote ‚Exadata is still Oracle!‘ is from a competitor and not from our Marketing 🙂
For DBAs, it is similar as moving from a Single-Instance system to RAC. Some additional things to learn, like Smart Scan and Storage Indexes. Over time, the DBAs on that team may incorporate the know-how they gather at first from their named contacts of the other groups. The pragmatic EDBA approach is likely if Exadata is seen as a strategic platform, but the effort to build a DBMA team is regarded to high respectively the internal organizational structure is not flexible enough to start with the third approach. Administrative responsiveness and agility are already higher here as with the first approach, though.
3. The Database Machine Administration (DBMA) Team
Either the EDBA team evolves over time into a DBMA team or you start straight with this approach, typically by assigning some Admins from the Storage/System/Network groups to the DBMA team and let all team members cross-train in the three areas:
 This gives you the optimal administrative responsiveness and agility for your business requirements related to Exadata, which is what the majority of customers will probably want to achieve – at least in the long term. You will see this approach most likely if Exadata is supposed to be a strategic platform at your site. The good news (in my opinion) for the team members here is that they all will enlarge their mental horizon and gather new and exciting skills!
This gives you the optimal administrative responsiveness and agility for your business requirements related to Exadata, which is what the majority of customers will probably want to achieve – at least in the long term. You will see this approach most likely if Exadata is supposed to be a strategic platform at your site. The good news (in my opinion) for the team members here is that they all will enlarge their mental horizon and gather new and exciting skills!
How to manage Exadata?
Regardless of your particular approach, the most important single administrative tool will be the Enterprise Manager 12C:
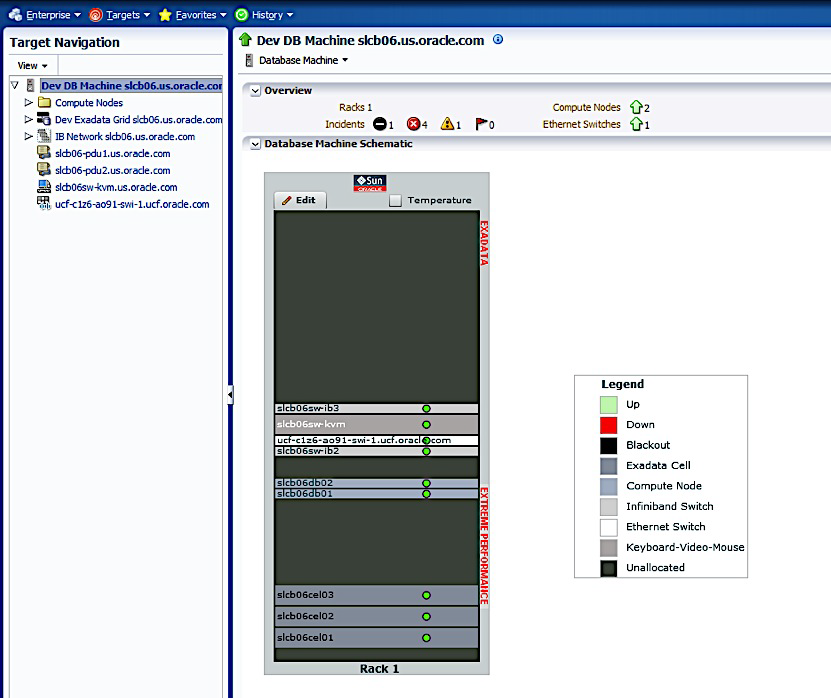 You can see that you can manage all Exadata components with a single, centralized tool. The picture is from our excellent Whitepaper Oracle Enterprise Manager 12c: Oracle Exadata Discovery Cookbook
You can see that you can manage all Exadata components with a single, centralized tool. The picture is from our excellent Whitepaper Oracle Enterprise Manager 12c: Oracle Exadata Discovery Cookbook
Much of the above, especially the terms EDBA and DBMA can be found in our Whitepaper Operational Impact of Deploying an Oracle Engineered System (Exadata) – for some reason it is presently only available through our Oracle Partner Network. It’s kind of our official ‚party line‘ about the topic, though. I’d also like to recommend Arup Nanda’s posting Who Manages the Exadata Machine? that contains related information as well.
Finally, let me highlight the offerings of Oracle University for Exadata – you will see that there is training available for any of the three approaches 🙂
Exadata X3 Key Points
This post will give a brief summary of the Exadata Database Machine X3 as it was announced at the Oracle Open World by Larry Ellision:
 (URL above is the complete Keynote; X3 announcement comes at 31:29)
(URL above is the complete Keynote; X3 announcement comes at 31:29)
The X3 Storage Servers have 4 times the Flash Capacity than X2: Each cell comes with 1600 GB, using Oracle’s Sun Flash Accelerator F40 PCIe Card now
 The X3 Database Servers have now 2 x Eight-Core Intel® Xeon® E5-2690(SandyBridge) Processors instead of 2 x Six-Cores in X2
The X3 Database Servers have now 2 x Eight-Core Intel® Xeon® E5-2690(SandyBridge) Processors instead of 2 x Six-Cores in X2

They have 128 GB memory each, instead of 96 GB on X2
The price of an X3 Rack remains the same except for the Software Licenses that are computed by the number of cores.
The X3 Entry Level Rack is now 1/8 Rack. It has got the same hardware as a 1/4 rack, but half of the cores, memory and storage capacity disabled.
Not only on X3, the Flash Cache will now work as a Write Back Cache. Older versions will be enabled to use Write Back Flash Cache with a Software Update.
More details:
Pickleball spielen auf YouTube


