Beiträge getaggt mit Data Warehouse
How Partial Indexing helps you save space in #Oracle 12c

Over time certain partitions may become less popular. In 12c, you don’t have to index these partitions anymore! This can save huge amounts of space and is one of the best 12c New Features in my opinion. Really a big deal if you are working with range partitioned tables where the phenomenon of old ranges becoming unpopular is very common. Let’s have a look, first at the problem:
SQL> select segment_name,partition_name ,bytes/1024/1024 from user_segments
where segment_name like '%OLD';
SEGMENT_NA PARTITION_ BYTES/1024/1024
---------- ---------- ---------------
GLOBAL_OLD 96
LOCAL_OLD Q4 22
LOCAL_OLD Q3 22
LOCAL_OLD Q2 22
LOCAL_OLD Q1 22
Without the New Feature, every part of the table is being indexed like shown on the below picture:

Ordinary Indexes on a partitioned table
Say partitions Q1, Q2 and Q3 are not popular any more, only Q4 is accessed frequently. In 12c I can do this:
SQL> alter table sales_range modify partition q1 indexing off; Table altered. SQL> alter table sales_range modify partition q2 indexing off; Table altered. SQL> alter table sales_range modify partition q3 indexing off; Table altered.
This alone doesn’t affect indexes, though. They must be created with the new INDEXING PARTIAL clause now:
SQL> drop index local_old; Index dropped. SQL> drop index global_old; Index dropped. SQL> create index local_new on sales_range(time_id) indexing partial local nologging; Index created. SQL> create index global_new on sales_range(name) global indexing partial nologging; Index created.
You may notice that these commands execute much faster now because less I/O needs to be done. And there is way less space consumed:
SQL> select segment_name,partition_name ,bytes/1024/1024 from user_segments
where segment_name like '%NEW';
SEGMENT_NA PARTITION_ BYTES/1024/1024
---------- ---------- ---------------
LOCAL_NEW Q4 22
GLOBAL_NEW 24
That’s because the indexes look like this now:

Partial Indexes
Instead of dropping the old index you can also change it into using the New Feature:
SQL> select segment_name,partition_name ,bytes/1024/1024 from user_segments
where segment_name like '%OLD%';
SEGMENT_NA PARTITION_ BYTES/1024/1024
---------- ---------- ---------------
GLOBAL_OLD 96
LOCAL_OLD Q4 22
LOCAL_OLD Q3 22
LOCAL_OLD Q2 22
LOCAL_OLD Q1 22
SQL> alter index LOCAL_OLD indexing partial;
Index altered.
For a LOCAL index, that frees the space from the unpopular partitions immediately:
SQL> select segment_name,partition_name ,bytes/1024/1024 from user_segments
where segment_name like '%OLD%';
SEGMENT_NA PARTITION_ BYTES/1024/1024
---------- ---------- ---------------
GLOBAL_OLD 96
LOCAL_OLD Q4 22
That is different with a GLOBAL index:
SQL> alter index GLOBAL_OLD indexing partial;
Index altered.
SQL> select segment_name,partition_name ,bytes/1024/1024 from user_segments
where segment_name like '%OLD%';
SEGMENT_NA PARTITION_ BYTES/1024/1024
---------- ---------- ---------------
GLOBAL_OLD 96
LOCAL_OLD Q4 22
Still uses as much space as before, but now this releases space from unpopular parts of the index:
SQL> alter index global_old rebuild indexing partial; Index altered. SQL> select segment_name,partition_name ,bytes/1024/1024 from user_segments where segment_name like '%OLD%'; SEGMENT_NA PARTITION_ BYTES/1024/1024 ---------- ---------- --------------- LOCAL_OLD Q4 22 GLOBAL_OLD 24
Cool 12c New Feature, isn’t it? 🙂
How to change RANGE- to INTERVAL-Partitioning in #Oracle

An existing RANGE partitioned table can easily be changed to be INTERVAL partitioned with the SET INTERVAL command. My table has been created initially like this:
SQL> create table sales_range (id number, name varchar2(20),
amount_sold number, shop varchar2(20), time_id date)
partition by range (time_id)
(
partition q1 values less than (to_date('01.04.2016','dd.mm.yyyy')),
partition q2 values less than (to_date('01.07.2016','dd.mm.yyyy')),
partition q3 values less than (to_date('01.10.2016','dd.mm.yyyy')),
partition q4 values less than (to_date('01.01.2017','dd.mm.yyyy'))
);
That way, an insert that falls out of the last existing range fails:
SQL> insert into sales_range values (4000001,'Hesse',1999,'Birmingham',to_date('27.01.2017','dd.mm.yyyy'));
insert into sales_range values (4000001,'Hesse',1999,'Birmingham',to_date('27.01.2017','dd.mm.yyyy'))
*
ERROR at line 1:
ORA-14400: inserted partition key does not map to any partition
Now instead of having to add a new range each time, the table can be changed to add that new range automatically if new rows require them. In other words, the 11g Feature Interval Partitioning can be added after the initial creation of the table:
SQL> alter table sales_range set interval(numtoYMinterval(3,'MONTH'));
Table altered.
SQL> insert into sales_range values (4000001,'Hesse',1999,'Birmingham',to_date('27.01.2017','dd.mm.yyyy'));
1 row created.
SQL> commit;
Commit complete.
SQL> col partition_name for a10
SQL> select partition_name from user_tab_partitions where table_name='SALES_RANGE';
PARTITION_
----------
SYS_P249
Q4
Q3
Q2
Q1
This is documented, of course. But the ALTER TABLE command is probably one of the most voluminous, so good luck in working your way through it until you find that part 😉
Why your Parallel DML is slower than you thought
In the Data Warehouse Administration course that I delivered this week, one topic was Parallel Operations. Queries, DDL and DML can be done in parallel, but DML is special: You need to enable it for your session! This is reflected in v$session with the three columns PQ_STATUS, PDDL_STATUS and PDML_STATUS. Unlike the other two, PDML_STATUS defaults to disabled. It requires not only a parallel degree on the table respectively a parallel hint inside the statement, but additionally a command like ALTER SESSION ENABLE PARALLEL DML; Look what happens when I run an UPDATE with or without that command:
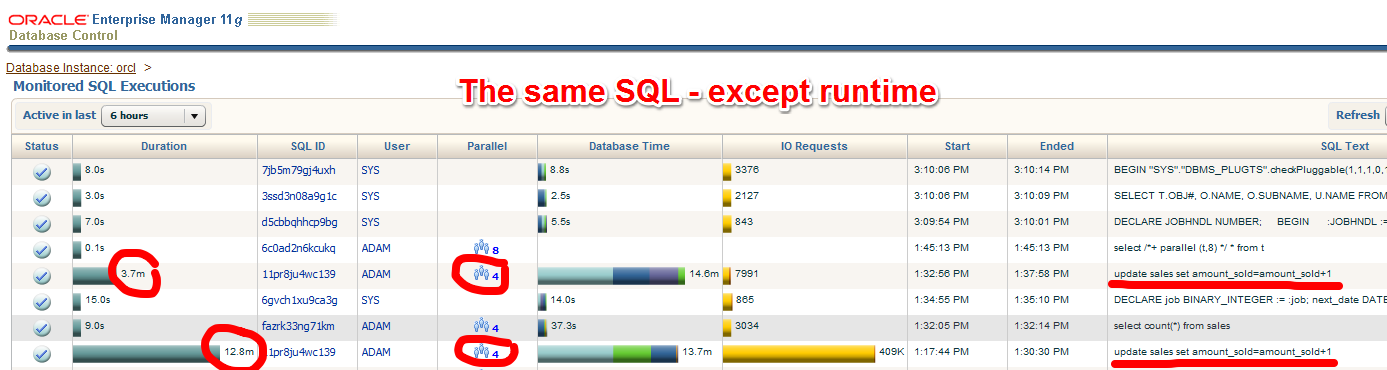 The table sales has a parallel degree of 4. The two marked statements seem to be identical – and they are. But the second has a much longer runtime. Why is that?
The table sales has a parallel degree of 4. The two marked statements seem to be identical – and they are. But the second has a much longer runtime. Why is that?
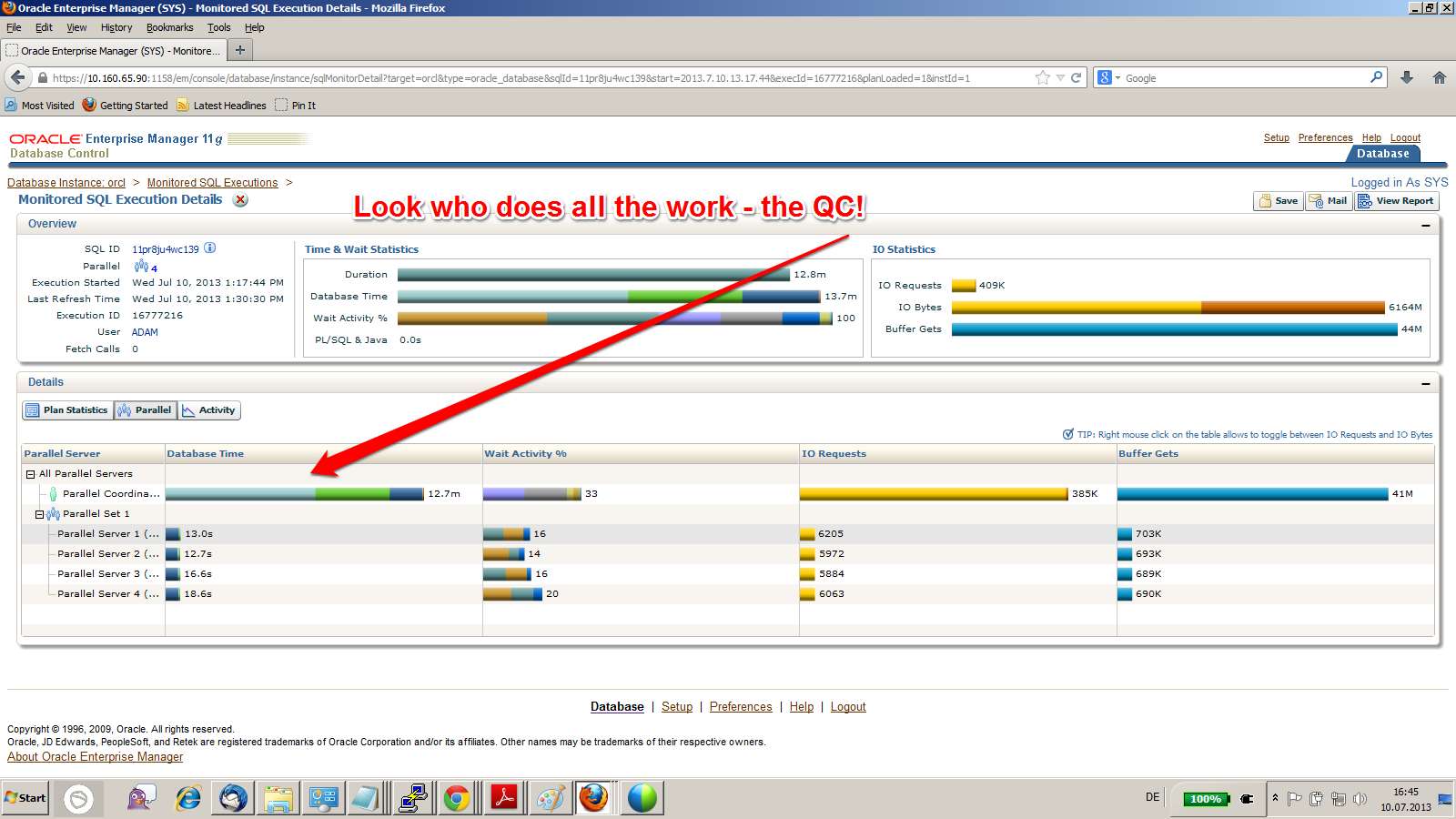 It’s because Parallel DML is disabled in that session. The fetching of the rows can be done in parallel, but the Query Coordinator (QC) needs to do the update! That is of course not efficient. The mean thing is that you see actually Parallel Processes (PXs) running and appearing in the execution plan, so this may look like it does what it is supposed to – but is does NOT. Here is how it should be, with the correct ALTER SESSION ENABLE PARALLEL DML before the update:
It’s because Parallel DML is disabled in that session. The fetching of the rows can be done in parallel, but the Query Coordinator (QC) needs to do the update! That is of course not efficient. The mean thing is that you see actually Parallel Processes (PXs) running and appearing in the execution plan, so this may look like it does what it is supposed to – but is does NOT. Here is how it should be, with the correct ALTER SESSION ENABLE PARALLEL DML before the update:
 The QC does only the job of coordinating the PXs here that do both, fetching and updating the rows now. Result is a way faster execution time. I’m sure you knew that already, but just in case 😉
The QC does only the job of coordinating the PXs here that do both, fetching and updating the rows now. Result is a way faster execution time. I’m sure you knew that already, but just in case 😉
Pickleball spielen auf YouTube


