Automatic Storage Management (ASM) is becoming the standard for good reasons. Still, the way it mirrors remains a mystery for many customers I encounter, so I decided to cover it briefly here.
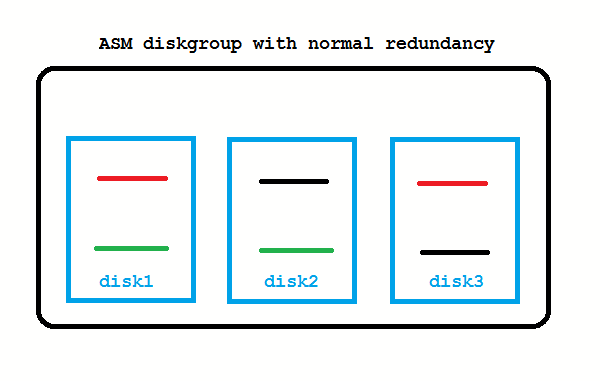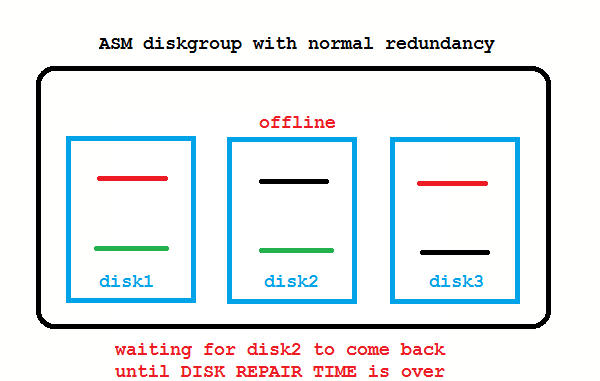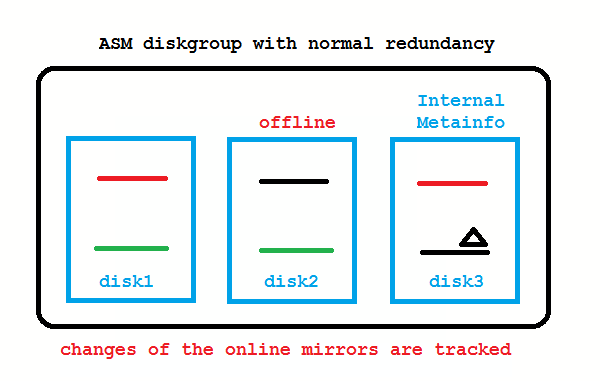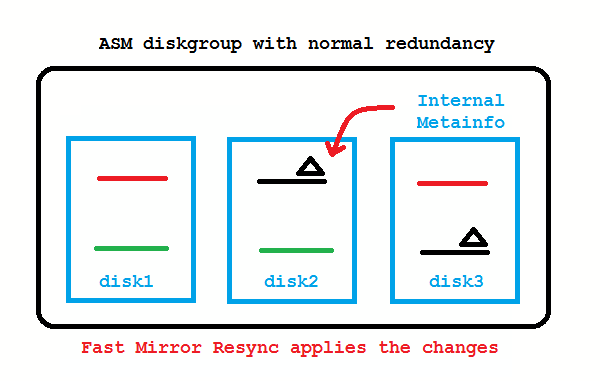
ASM Basics: What does normal redundancy mean at all?

It means that every stripe is mirrored once. There is a primary on one disk and a mirror on another disk. All stripes are spread across all disks. High redundancy would mean that every primary stripe has two mirrors, each on another disk. Obviously, the mirroring reduces the usable capacity: It’s one half of the raw capacity for normal redundancy and one third for high redundancy. The normal redundancy as on the picture safeguards against the loss of any one disk.
ASM Basics: Spare capacity
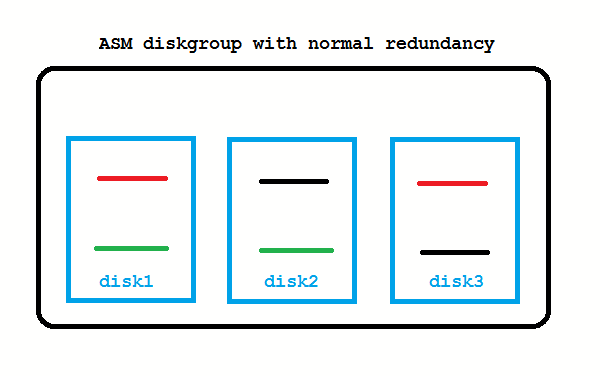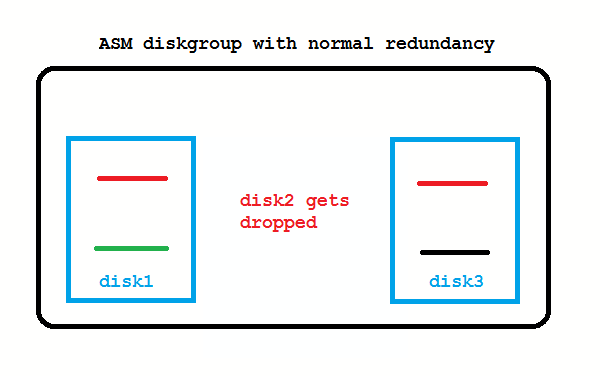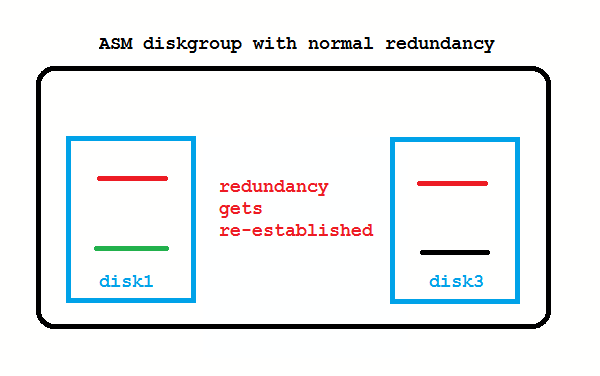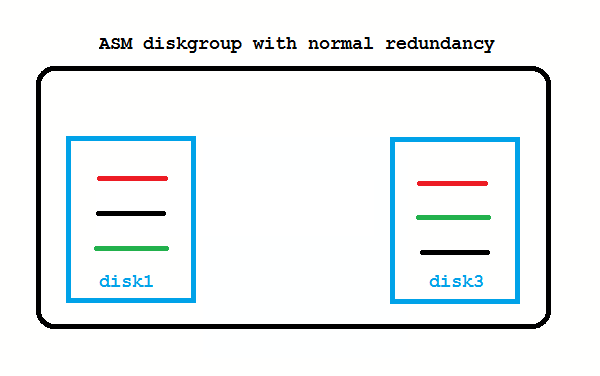
When disks are lost, ASM tries to re-establish redundancy again. Instead of using spare disks, it uses spare capacity. If enough free space in the diskgroup is left (worth the capacity of one disk) that works as on the picture above.
ASM 11g New Feature: DISK_REPAIR_TIME
What if the disk from the picture above is only temporarily offline and comes back online after a short while? These transient failures have been an issue in 10g, because the disk got immediately dropped, followed by a rebalancing to re-establish redundancy. Afterwards an administrator needed to add the disk back to the diskgroup which causes again a rebalancing. To address these transient failures, Fast Mirror Resync was introduced:
No administrator action required if the disk comes back before DISK_REPAIR_TIME (default is 3.6 hours) is over. If you don’t like that, setting DISK_REPAIR_TIME=0 brings back the 10g behavior.
ASM 12c New Feature: FAILGROUP_REPAIR_TIME
If you do not specify failure groups explicitly, each ASM disk is its own failgroup. Failgroups are the entities across which mirroring is done. In other words: A mirror must always be in another failgroup. So if you create proper failgroups, ASM can mirror according to your storage layout. Say your storage consists of four disk arrays (each with two disks) like on the picture below:

That is not yet the new thing, failgroups have been possible in 10g already. New is that you can now use the Fast Mirror Resync feature also on the failgroup layer with the 12c diskgroup attribute FAILGROUP_REPAIR_TIME. It defaults to 24 hours.
So if maintenance needs to be done with the disk array from the example, this can take up to 24 hours before the failgroup gets dropped.
I hope you found the explanation helpful, many more details are here 🙂



#1 von bugnvl am Januar 19, 2015 - 09:20
First, thank you fir sharing fantastic articles. And 2nd with ASM we are observing issues with force disk drop n disk group dismount. From my observation, looks to be related to _asm_hbeatiowait. Could you please share some explanation on how this is being fixed with a patch 18522509 patch, which doesn’t change parameter either at os(linux 60 sec) or at asm (15 default).
Thanks
#2 von bugnvl am Januar 19, 2015 - 09:22
Disks in focus are ‚Normal‘ redundancy only. External redundancy disk n group are stable n safe on the same cluster.
Thanks
Arun.
#3 von A Rahim Khan am Februar 7, 2015 - 19:56
Reblogged this on Oracle Learnings | A Rahim Khan.
#4 von Mastan am Mai 24, 2017 - 06:58
Same way your explain high redundancy in mirroring and striping in asm
#5 von aitorito am Dezember 5, 2017 - 14:11
Thanks UWE…
What do you prefer, cabinet mirroring for physical disks or server mirroring for asmdisks?