Beiträge getaggt mit Performance Tuning
Remedy for bad hints: SQL Profiles
This is the second week in a row that I am in Berlin, this time teaching a 10g Performance Tuning course. Fortunately, the weather this week is a lot better 🙂
Well, one really great improvement of the 10g version was the introduction of SQL Profiles. They can give the optimizer additional information, but they do not determine an execution plan like hints or stored outlines do. Using the SQL Tuning Advisor for high load statements may (not for sure) lead to the recommendation to create such a SQL Profile that may very well speed up that query dramatically. A special case is, if you have statements hard coded in applications that use hints which are not (longer) good. You can hint the optimizer not to use those bad hints with SQL Profiles 🙂 Here is an example.
I have created a larger sales table with a very skewed channel_id column:
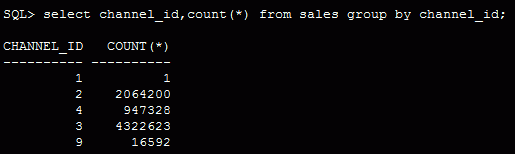
I have also informed the optimizer of that skew by creating histograms. Also, there is an index on the channel_id column, that is used by the following statement:
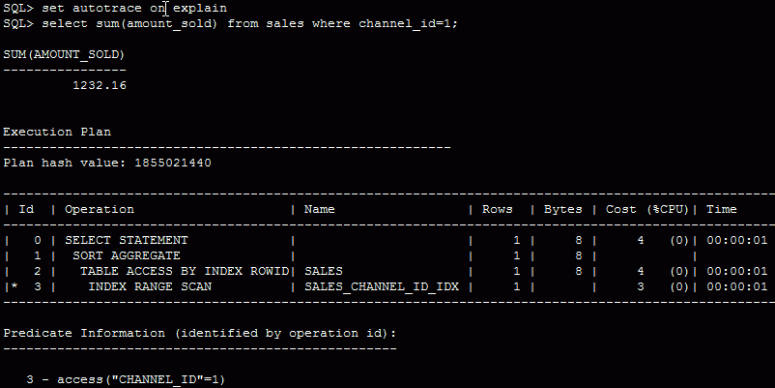
But not by following statement – which is perfectly ok, the index access would be slower as the FTS here.
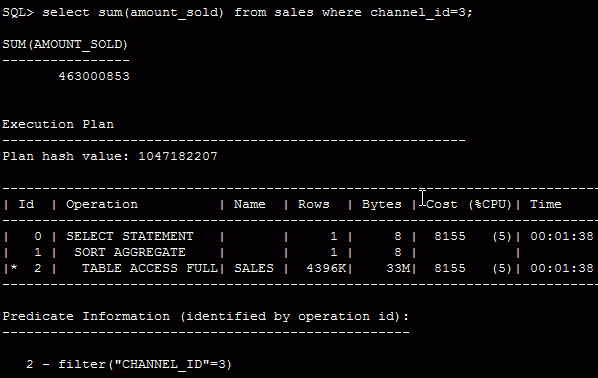
Now I force the optimizer to use that index with a hint:

In fact, this is bad, as we can see by runtime comparison:
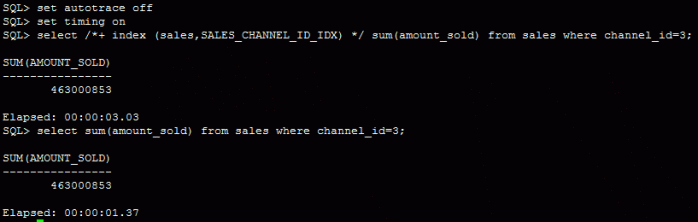
But let’s assume that hint is already hard coded in an application running against my Database.
Then I can use the SQL Tuning Advisor:
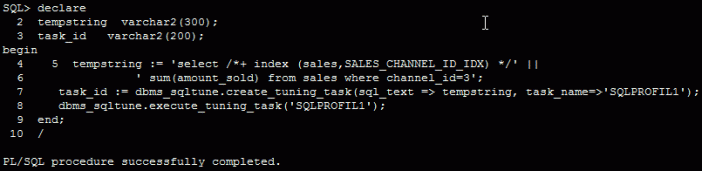
The following is the recommendation of the SQL Tuning Advisor. It recommends a SQL Profile:
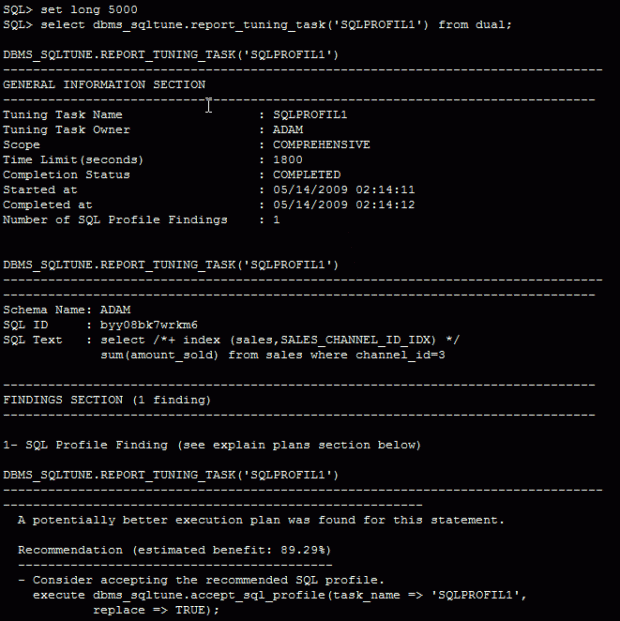
I decide to accept that with the above accept_sql_profile call.
Then comes again the hard coded statement with the index hint:
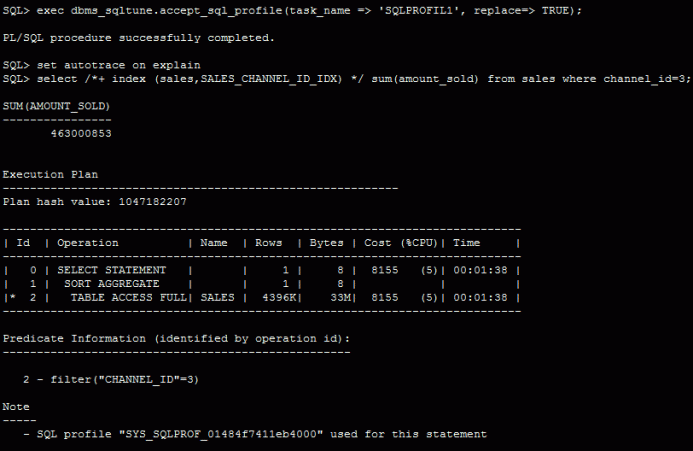
As you see, the SQL Profile makes it possible for the optimizer to ignore the hint!
Adaptive Cursor Sharing
I am back in Germany, teaching an 11g Performance Tuning course in Munich. There are several New Features in the 11g version related to Performance Tuning, one of them is Adaptive Cursor Sharing.
It adresses the problem that can occurr in earlier versions if you use bindvariables together with indexes on columns that have skewed values. Typically, you create histograms on skewed columns to notify the optimizer of the skew, so that it can use an index if rare values are asked and make a FTS if values with a low selectivity are used.
Bindvariables used to cross that approach – even Bind Peeking did not always resolve the issue, because the first content of the peeked bindvarible determined all future execution plans.
With 11g, this behaviour has changed. In other words: You can have multiple execution plans now with the same statement that uses bindvariables (with different contents). You may find a very nice explanation of this 11g New Feature from the guys who invented it here.
Pickleball spielen auf YouTube


